
Principal Software Engineers at ComplyAdvantage need to paint with a broad brush. Every week we must apply the full gamut of skills learnt during our careers as a Software Engineer. From writing code to technical design. Mentoring to managing stakeholders. Reviewing merge (pull) requests for a Junior Software Engineer to presenting at the Executive level.
I’m Mark. That's me in with the light shirt and crossed arms in the header image above, and I am a Principal Software Engineer here at ComplyAdvantage aligned to our Platform Tribe (which is responsible for platform-level services). A frequent question I get when I tell someone my level is “What does it mean to be a Principal Software Engineer?”. The intelligent quip is “I’ll let you know when I figure it out”. Every week is different, but this is a fairly typical snapshot of my life in this role. Although every Principal Software Engineer’s life is different, I hope I can partially demystify some responsibilities of this role.
A warning in advance - this is a long post - I've tried to capture as much of my week as possible with enough detail to communicate not just what but also why.
This week, I am also the out-of-hours on-call for one of our products. At ComplyAdvantage, even Principal Software Engineers can be on an out-of-hours on-call rota. This allows us to keep perspective and up to date with the challenges that can affect the day-to-day operations of our systems. You will see this pop up during the week.
Monday
A day of prototyping and perspectives
8:30am: Protocol Buffers
At ComplyAdvantage we use Protocol Buffers (protobuf) to model our internal API gRPC calls and messages sent via Kafka. All our protobuf schemas live in a monorepo. Libraries are published for Kotlin (our primary product development language), Python (the primary language for our data tribe and data scientists), Typescript (our primary Front-End language, but also some legacy services) and Golang (used by some legacy systems) whenever a protobuf schema change is made.
One of our challenges is that we are unable to independently version these libraries within the monorepo. This makes it hard to communicate the types of changes being made to individual libraries. Most specifically, it means we cannot correctly identify library-specific breaking changes. A team could upgrade a simple patch release and experience a breaking change, or could upgrade a major version that doesn’t contain a breaking change for that specific library.

This has become an important issue to resolve, as an outdated dependency in our Kotlin library now hampers our adoption of newer protobuf features. However, removing it requires publishing a breaking change - a risky move when our versioning system can't warn consumers that what looks like a simple patch is anything but.
A few weeks ago, I proposed a change to the way we version these libraries so we can independently version each library using Semantic Versioning. Today, I am prototyping the entire monorepo semantic release process in a proof of concept repository to understand exactly how to apply this within our GitLab CI/CD process with minimal disruption to teams using it.

This work continues throughout the day, except for when I am in meetings.
10:30am: Weekly catchup for one of our strategic initiatives
At 10:30am, all teams involved in this initiative get together to share status updates face-to-face. Although we track everything within our project management system, the face time is essential to ensure nothing slips through the cracks, and teams can request help when needed.
As a Principal Software Engineer I am an Individual Contributor, so I am not directly involved in managing the delivery of any particular item for this initiative. My role in this meeting is largely to listen, and help clarify questions or offer offline help to teams as needed.
Today, I don’t need to get involved, but the meeting allows me to broadly understand what’s happened in the last week and validate that I do not need to get involved imminently with any particular team.
2pm: Celebrating and learning (fortnightly demo)
Every second Monday the entire engineering department get together to do a show-and-tell. Given the technical audience, this is a time to celebrate forward progress at any level. Demonstrations range from Junior Engineers showcasing a new API using Postman or curl all the way to Product Managers doing fully interactive demonstrations of new features in our product Web Apps.
For my role in the Platform Tribe, these demos are a data-gathering exercise. I'm listening for the real-world friction points. When an engineer says, "we had to build a custom script for this," it tells me our platform might be missing a feature. When a team shows a novel way of using one of our services, it gives me ideas for how we can better support other teams. So while I'm mostly a quiet observer in the session itself, the notes I take can translate into new tickets for the Platform backlog or inspire a change in our technical roadmap, ensuring that what we build is directly addressing the evolving needs of our product teams.
3pm: Back to Protocol Buffers
For the rest of the day I am back to working on the Protocol Buffers versioning changes. By the time I sign off the day I have a working prototype, and all that's left is planning for how to roll it out into our primary repository.
Tuesday
People, platforms, and process
8:30am: More Protocol Buffers
This will be a theme for the week. With a working prototype, I focus on planning how to roll it out to our primary repository with minimal disruption. I settle on keeping the existing versioning system in place while I add new pieces of the build pipeline, and once everything is working, wiring up the new versions to the published libraries.
I am ready to start implementing this in the real monorepo, but the rest of my day is pretty full, so that will need to wait till tomorrow.
10am: Growing the team
One of the responsibilities of a Principal Software Engineer, at any organisation, not just ours, is to help increase the impact of other engineers. This morning I agree to a new mentoring arrangement with a Staff Software Engineer, and I am looking forward to getting to know them better over the next few months!

Next up is a regular mentoring session with a Senior Engineer. After some chat about current projects, we speak about some organisational changes and how this will impact their goals for the rest of year. It can be hard for any Software Engineer to know if they are doing everything they need in order to progress to the next step of our Software Engineer career pathway. Thankfully, this engineer is proactive and is tracking their achievements and mapping them to our career pathway which helps them have more meaningful discussions with their line manager. I agree to continue reviewing the Engineer's tracker, and suggest some improvements to the way they can quantify the business impact of some of their examples.
11:30am: To wrap or not to wrap
One of our teams is using AI Evals in order to assess the accuracy and reliability of a product feature that utilises a Large Language Model as part of its implementation. They had been using a LangSmith wrapper library introduced by a partner, but were questioning whether the complexity of the library was necessary for their specific use case.
After a brief discussion it was clear that there was no benefit to continuing to use the library in our specific scenario, so we agreed to drop it entirely. This will simplify the team's technology stack slightly and decrease the number of things team members need to understand when working on the project.
1pm: Weekly API review time
At ComplyAdvantage all API changes need to go through review to ensure we maintain a consistent and cohesive set of APIs for our clients. Our current process involves a weekly meeting where stakeholders for all proposed changes gather to discuss them. These meetings are facilitated by a core group of people - the Engineering Manager of our Platform API team, one or more Principal Software Engineers, and a Senior Frontend Software Engineer. For each item under review a representative Software Engineer and Product Manager from each team with a change attends to facilitate discussion.
Although these sessions are primarily focused on the API surface area of a feature or domain, background context is frequently presented from a Product Requirement Document or Technical Design Document which aids in putting the changes into context.
These meetings are also used as a catalyst for identifying or proposing changes to our internal API design guidelines documentation. Occasionally we will find ourselves in disagreement on something that is ambiguous in our API design guidelines and these meetings are used to nut out those details.
Today we only had a single agenda item - an exploratory initial proposal for a new domain within Mesh - our single, AI-driven financial crime platform. The team proposed some new APIs to promote discussion and took away some action items to refine the current proposal.
2pm: Technology Blog Editorial Committee
At ComplyAdvantage we encourage all of our Engineers to write. This promotes knowledge sharing across the company and improves written communication across the board. We have an internal blog that anyone is able to post to without restriction. We also have a public technology blog (the one you're reading right now!). All content from the public blog is sourced from our internal blog.
The blog editorial committee is an administrative group chaired by a member of our Technology Operations department. The primary members are our Principal and Staff Engineers.
Every internal blog post is assigned a reviewer from the editorial committee. Their job is to assess the suitability for our public blog, and if suitable work with the author to refine the post. Rework of posts suitable for our public blog largely consists of reframing the posts to remove assumptions made by the author as to the audience of the post.
I'm assigned one post to review, which I add to my to-do list for this week.
2:30pm: Facilitated design review
I joined a facilitated design review for a new feature. In these sessions, my role is often to absorb the context and serve as a sanity check. I listen for the technical trade-offs being made and ensure they align with our long-term goals for the platform. The team presented a well-considered design, and I left feeling confident in their approach and better informed about an important upcoming change to our product.
Wednesday
Shipping and strategy
8:30am: Protobuf versioning makes its way to production
Today is the day I get to implement the protocol buffers changes prototyped on Monday, leveraging the Semantic Release tooling and monorepo extensions. Given our protobuf project is touched by almost all teams in ComplyAdvantage it’s important for this change to be as smooth as possible.
Following my plan from Tuesday morning, I roll out the changes over the course of the day, going one library at a time. I start off with our protobuf schema and descriptors themselves. I then manage the overall risk of the change by rolling out the library changes in order of least to most consumed within the company.
9am: Soft deletion design discussion
One of the teams behind Mesh has a design proposal for the soft deletion of data within one of their services. I have a call with one of the Senior Engineers who runs me through some design options and the direction that they are considering. The design under consideration leverages Spring Batch patterns (which they have used elsewhere) and accounts for scenarios where they need to delete large volumes of data.
We discuss the reasons for their design choices, focusing on whether there is anything they can do with less effort but remain low impact as there are a number of options on the table. I reflected on the fact there is what I think could be a potential solution to their problem, but it’s not on our Tech Radar (our internal guide to recommended technologies). In order to avoid tech proliferation, all significant new technologies need to go through our Tech Review Board in order to make it onto our Tech Radar and this one is on the horizon but not there yet.
We conclude by agreeing its worth exploring some simpler options in more detail before moving ahead with Spring Batch.
10am: Deep-dive into code review
I am drafted in to review a Merge Request for a team who are making a change to their YugabyteDB Data model. Given YugabyteDB is a Distributed SQL database, new indexes require a careful hand in order to ensure they will remain performant as the scale of our platform grows. Over the last 2.5 years we’ve learnt a lot about how to model data in YugabyteDB. Our engineers generally know the right things to do, however we still keep Principal Engineers in the loop for a final check over any index changes, just to be sure. A bad index can have a large impact on the performance of the database.
In this case, my feedback focused on clarity and intent. I suggested they be explicit about the role of each column within the primary key index.
CREATE TABLE orders AS (
account UUID,
identifier UUID,
PRIMARY KEY (account, identifier)
)
Example 1 above: ✖ The intent is not clear and, in fact, does not do what the author intended. This index will perform poorly as all data for a single account will be on a single node.
CREATE TABLE orders AS (
account UUID,
identifier UUID,
PRIMARY KEY (
(account, identifier) HASH
)
)Example 2 above : ✔ Explicitly specifying HASH makes the intent clear and matches the intent of the author. This index will perform well as orders will be well distributed across the cluster.
See my Distributed SQL Summit 2024 presentation (Lessons from building AML and Fraud Detection with Distributed SQL) for more on this if you are interested in more detail.
These changes are quickly incorporated by the engineer in question and the Merge Request gets my Approval.
11am: Blog proofreading
Next, I have two blog posts in my review queue. For the first, an engineer has asked me to proofread a post destined for our internal blog. Luckily I’ve been asked to proofread before publication to our internal blog. This means I can put my Public Technology Blog Review Committee hat on and try to solve 2 problems at once. First, give the author feedback for the internal post, and second, ensure it’s framed correctly for the public tech blog at the same time. I give this one a thorough deep read and propose edits.
After working through this first blog post I need to give a high level review of another to determine if it’s suitable for inclusion in our public technology blog. My aim here isn’t to do a detailed proofread of the post, just to determine whether it could be included, and report back. In this case the post is a good candidate for our public blog, so I mark it as such on our tracker, let the author know, and schedule some time to do a full proofread on Friday.
1:30pm: Assisting the Implementation team
Our Implementation team guide clients through the process of on-boarding to our products and manage the technical aspects of a client’s relationship with us. They were proactively looking to build some diagnostic reports for a potential data scenario. We riff off a few ideas, weighing up the pro’s and con’s of approaches to implementing the report before finally settling on something that they can manage easily themselves.
1:45pm: Continue proto release work
I’m back to working through library releases, one at a time. This continues through the afternoon except for a short break to quickly re-review the blog post I proofread in the morning. The author has incorporated my feedback, and the revised post is great.
The protobuf releases continue through to the end of the day, by which point the job is done, and all libraries are now being released with independent version numbers. I feel relieved for this to be complete since there was a lot of moving parts.
Thursday
When plans change
2am: Night-time wake up
I get woken at 2am by my iPhone's “critical notification” chirp. Our automated alerting is notifying me that one of our systems has a database query running significantly longer than normal. I sign in to check. This query is part of some batch processing tasks. I spend the next few hours trying to figure out whether I can nudge PostgreSQL into choosing a more optimal query plan with no luck. Postgres is simply unable to correctly optimise some WHERE conditions that make use of jsonb equality no matter what I try.

I finally spot an interesting pattern in the data within the query which is causing a row count explosion which can easily be optimised away within the service’s code. This change will result in a simpler query for Postgres to deal with. Given the slow query isn’t causing any client impact I record the work required in a ticket and resolve to pick it up in the morning. Back to bed at 4:30am.
9:30am: Let’s implement this optimisation
I start a bit later than usual on account of being up in the middle of the night and move the ticket I created to In Progress. I spend the morning validating my change will have the impact I expect, and implementing the change. Given my change has no functional impact on the operation of the system, I am glad to see the current test suite will be sufficient for testing the behaviour post-change.
I then work through the process of getting the changes reviewed and release rolled out through our staging environments to the production. This ends up taking most of the rest of the day, mostly with background build and release processes, but in the end our metrics show the slow query issue has been completely resolved.

11am: Line Manager 1-1
I have a half hour 1-1 with my Line Manager, our Vice President of Engineering and head of both our Platform and Infrastructure Tribes. Although a Principal Engineer's work is somewhat self-directed - in the sense we are not embedded in a single team and are responsible for figuring out what we should be paying attention to and working on - I typically use this session to ensure I am aligned with my manager’s goals, and I am both heading in the direction they need me to be heading, and paying attention to the things that are important to them.
Like any 1-1 meeting, this is also my time to bring to my manager’s attention anything that I think they need to know about which is either currently impacting teams, or may impact in the future if not resolved, and today was no exception as we discussed a potential feature ownership issue which could cause a longer term problem if not addressed soon.
12:30pm: Tech Leadership Meeting Preparation
Every Friday morning the entire Tech Leadership team comes together. I’m up to present in one of the slots so the primary thing I work on, while not co-ordinating the service release in the background, is a short slide deck and demo.
Principal Engineers face a unique challenge in this meeting. Since we aren't managing a specific team, we can't give a project status report. Instead, our task is to create a presentation from scratch that is engaging, useful, and strategically relevant to a senior audience of the CTO, Directors, and Managers.
I manage to get the slides done by the end of the day.
2:30pm: Platform and Infrastructure Leadership Meeting
This weekly meeting brings together the VP of Engineering, Engineering Managers, and Principal Engineers in both our Platform and Infrastructure tribes. The agenda is typically driven by the attendees and put together in the morning leading up to the meeting with whatever people have on their mind.
The topics for this week's meeting are region-less URLs for our Mesh product (for any Clients reading, please start using mesh.complyadvantage.com and api.mesh.complyadvantage.com!), database optimisation, logging upgrades, a strategic refactoring of a messaging-related platform component and a discussion about the accuracy and use of percentile based metrics.
Friday
Strategy, bug fixes, and glue
9:00am: Tech Leadership Meeting
After my preparation yesterday, I am 3rd in the running order for today's meeting. I have decided to cover a couple of topics.
The first is a public service announcement for the Protocol Buffers versioning changes that I had implemented earlier in the week to reinforce the communications already delivered over Slack.
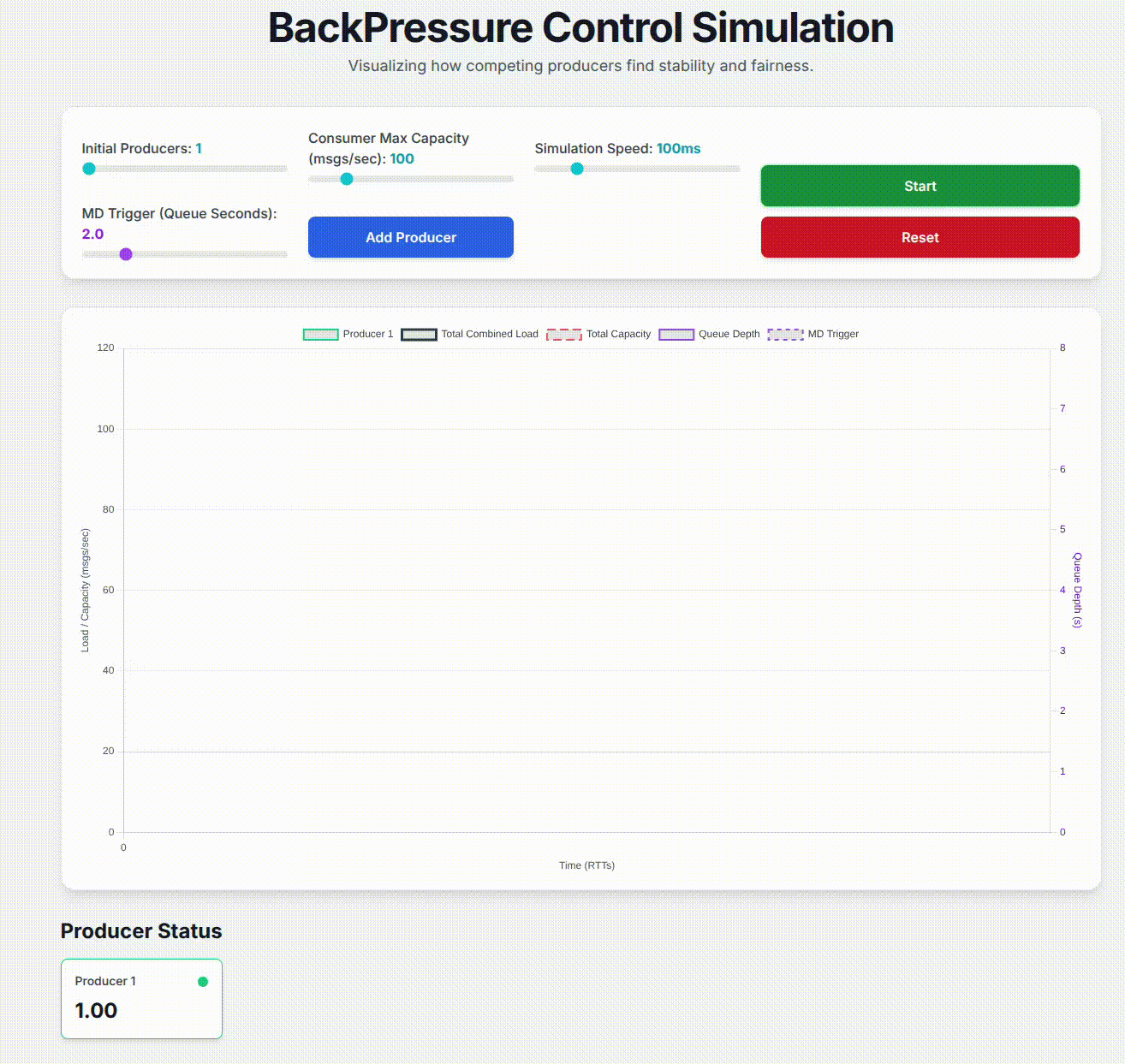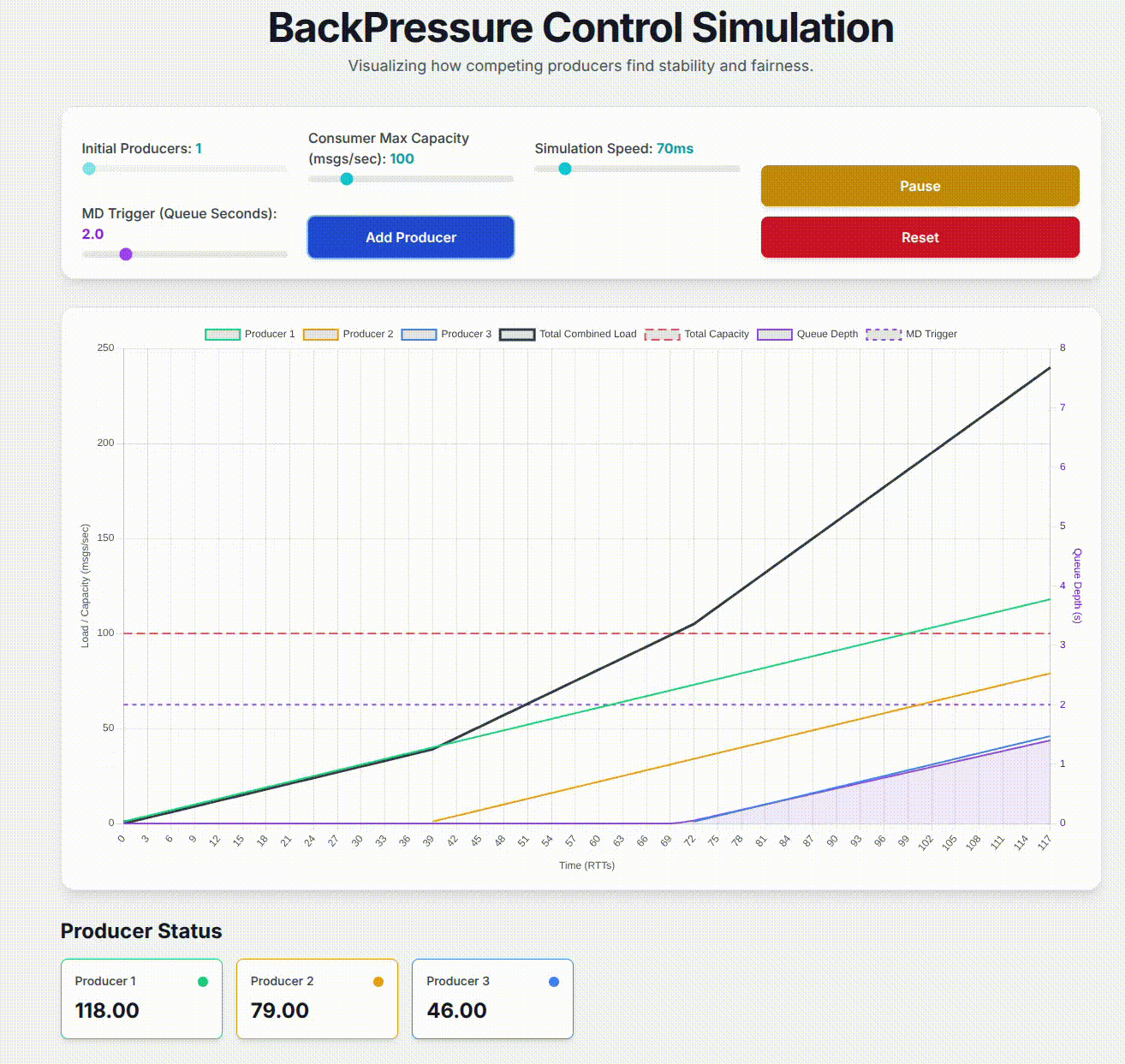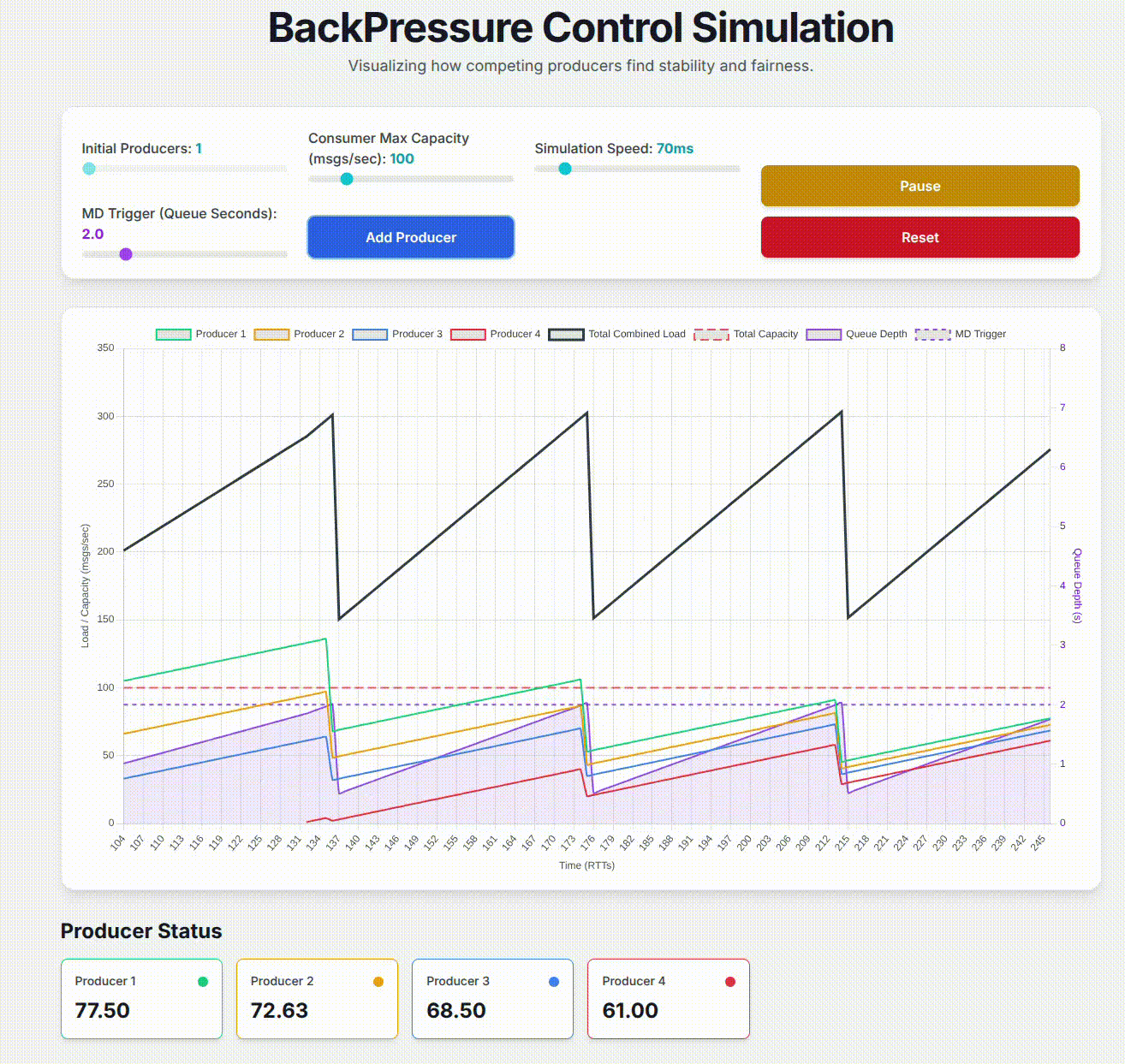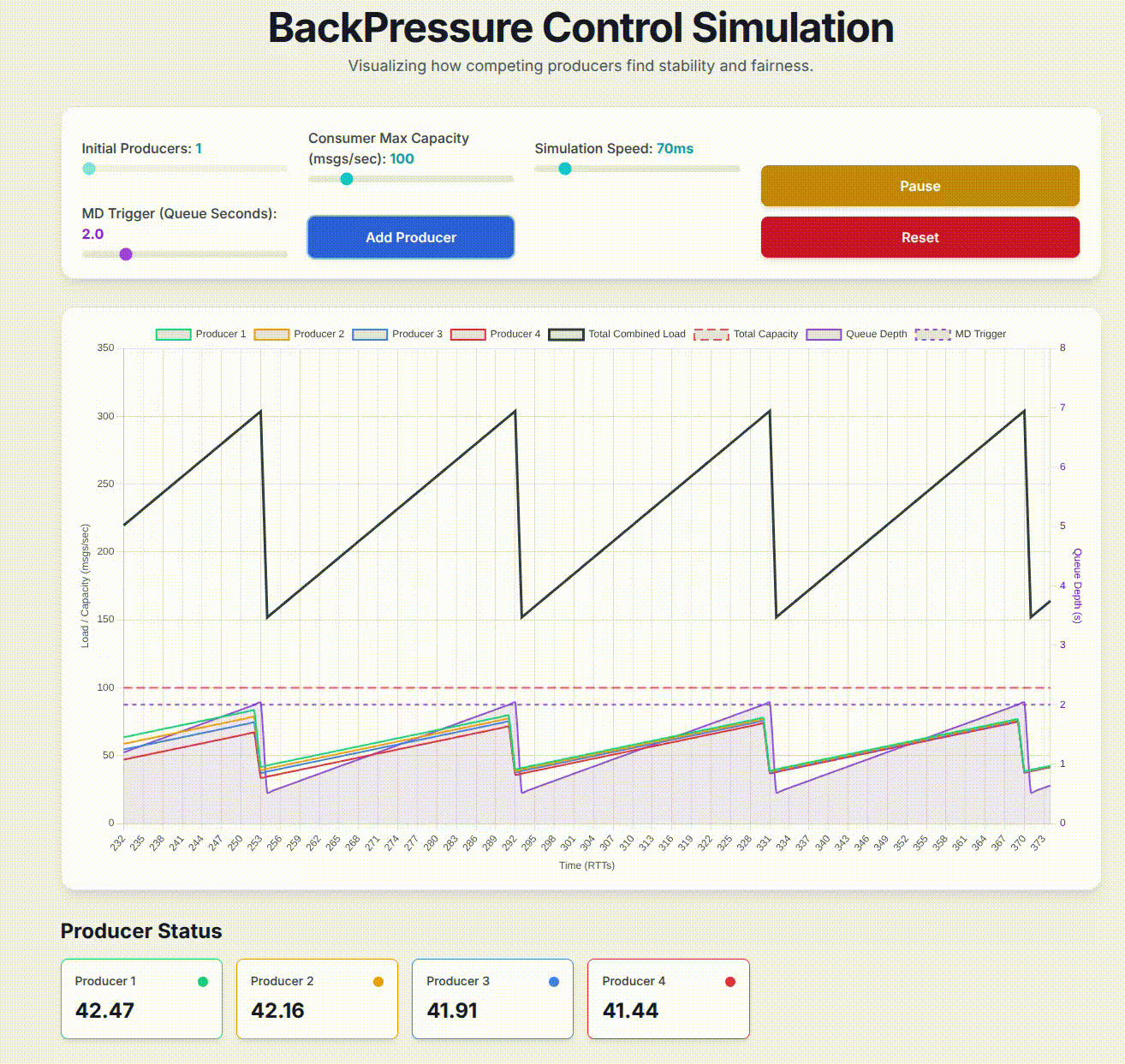
Second, I explained a technical proposal I have written regarding the addition of AIMD based back-pressure control to one of our services in order to allow multiple message producers to fairly share downstream capacity. I showcase how I used Google Gemini’s Canvas feature to build a working simulation of the back-pressure control design. This helped me visualize what I was proposing to confirm its effectiveness, and provide a concrete demonstration of how the design addressed specific problems that we were trying to solve. My goal in presenting this is to open people’s minds to the potential for using Large Language Models to enhance the messaging within technical designs.
11am: Protocol Buffers Bug fixing
There are a couple of small bugs with the release note generation after my implementation of the protobuf semantic versioning. I spend a bit of time squashing these bugs to ensure the release note generation for libraries includes the schema-change release notes. This ensures its clear what changes an individual library includes in the release.
2:15pm Blog Proofreading
I have 2 things to proofread this afternoon. The first is the final set of changes to the internal blog post I reviewed on Wednesday. The author has incorporated most of my feedback and provided 3 different alternatives for a specific section we were unsure about. I give my opinion on which alternative I prefer, and luckily we both agree. The author makes the final changes and the post is published at 3pm.
The second blog post is a full proofread of the post that is a candidate for our public technology blog. I spent about 45 minutes reading the post and providing feedback. The author agrees to review my feedback and make edits as they see fit. I will come back to this post when the edits have been made.
3:30pm: Glue
Glue. Those small tasks that keep things on track (See Tanya Reilly’s Being Glue). I have a few small ticket items to get done before I finish for the week. I need to provide some feedback on an internal portal being developed, so I do this. In addition, we are trying to match some software we are being invoiced for to it’s use within the technology department. I manage to track it down and initiate a discussion about whether we need to keep paying for the software given its light usage.
4pm: Ending the week early
I need to sign off a bit early today to pick up my daughter from a dance audition at school, so my week ends here. I record some weekly wrap-up notes in Logseq as a reminder to myself for the following week. This allows me to get off to a running start on Monday morning.
A week in review
As I reflect on this post while thinking about what to write in this conclusion, my mind wonders to the recently coined Expert Generalist (Joshi, Venkatraman & Fowler). This is certainly something to which I aspire in my work, and something I believe is a valuable skill for the role of Principal Software Engineer. I encourage you to read the linked article as a follow-on from this post.

So, to circle back to the question I get asked so often, "What does it mean to be a Principal Software Engineer?". Looking back at the week, I think one answer is that it’s about applying your experience at the right leverage point. On Monday, that leverage point was prototyping a fix for a long-standing challenge with our Protocol Buffers monorepo. On Thursday, it was being woken at 2 AM by an alert and digging into a PostgreSQL query plan to protect our system's performance. And on Tuesday, it was in the quieter moments, like helping a Senior Engineer quantify their achievements within our career pathway. Hands-on coding is still part of the job, but the core of the role is using experience to make the entire system - whether that's our software, our processes, or our people - healthier and more effective.