
Cluster resource management in Amazon EMR can be overwhelming, and the lack of implementation details/documentation makes it more complex.
Since I started working on Amazon EMR, I had doubts regarding multi-tenancy and resource management. Here, I'm sharing my experience working with EMR and configuring it at scale for ComplyAdvantage. This blog may help you to answer questions like
- How Amazon EMR manages resources under the hood.
- How does Amazon EMR scale automatically?
- How does Apache YARN work?
- How does Amazon EMR extend Apache YARN?
- How do multiple big-data clusters like Apache Flink, and Apache Spark share resources?
By the way, what is Amazon EMR?
Amazon EMR
Amazon EMR (Elastic Map-Reduce) is a cloud big-data platform running large-scale distributed data processing jobs. It's a managed cluster platform that simplifies running a big data framework like Hadoop, Jupyter, Ganglia, Hive, TensorFlow, HBase, Hue, Spark, Flink, Pig, Zookeeper, Phoenix, and many more.
How is the Amazon EMR cluster provisioned? One can provision an EMR cluster in several ways like in EC2, in EKS, in AWS Outpost, or Serverless. We are using EC2, as Flink is only supported by EC2 (at the time of writing), and in ComplyAdvantage we are heavy on Flink and Spark. However, the core concept remains the same.
Amazon EMR cluster resource management
Before we jump into our main topic, it is necessary to know a few basic components.
By default, EMR uses Apache YARN(Yet Another Resource Negotiator) for resource management.
Apache YARN is a project created to separate resource management and application/job management. This helps in managing resources consistently, instead of implementing resource management as part of tools like Apache Flink, Apache Spark, etc.
Components of YARN: (You'll later see how each of the components comes together in the EMR cluster)
- ResourceManager: is the global component for managing resources including - CPU, Memory, Disk, and Network. Resource manager has two components: Scheduler & ApplicationManager.
- Scheduler: is responsible for allocating resources to other running applications, based on availability. It provides no support for monitoring or tracking failed jobs. In EMR, the scheduler uses a pluggable policy which is responsible for partitioning the cluster resources among the various queues and applications.
- ApplicationManager: is responsible for accepting job submissions, and negotiating the first container for executing the application. It restarts the application in case of failure.
- NodeManager: is a per-machine daemon, responsible for managing containers, monitoring their resource usage, and reporting them back to ResourceManager/Scheduler.
- ApplicationMaster: is a YARN framework-specific library that is tasked to negotiate resources from the ResourceManager and work with NodeManagers to execute and monitor the tasks.
One last thing before we see how everything works together: EMR deploys its clusters across three different types of nodes, each having different roles and scales differently.
- Master/Primary nodes: do not scale, it can be either 1 or 3
- Core Nodes: ApplicationMasters for each application(Flink or Spark for example) are deployed here.
- Task Nodes: Task nodes add power to perform parallel computation tasks on data. In the case of Flink, task managers are deployed on the task nodes.
Let's connect the dots and take a glance at what we have discussed so far.
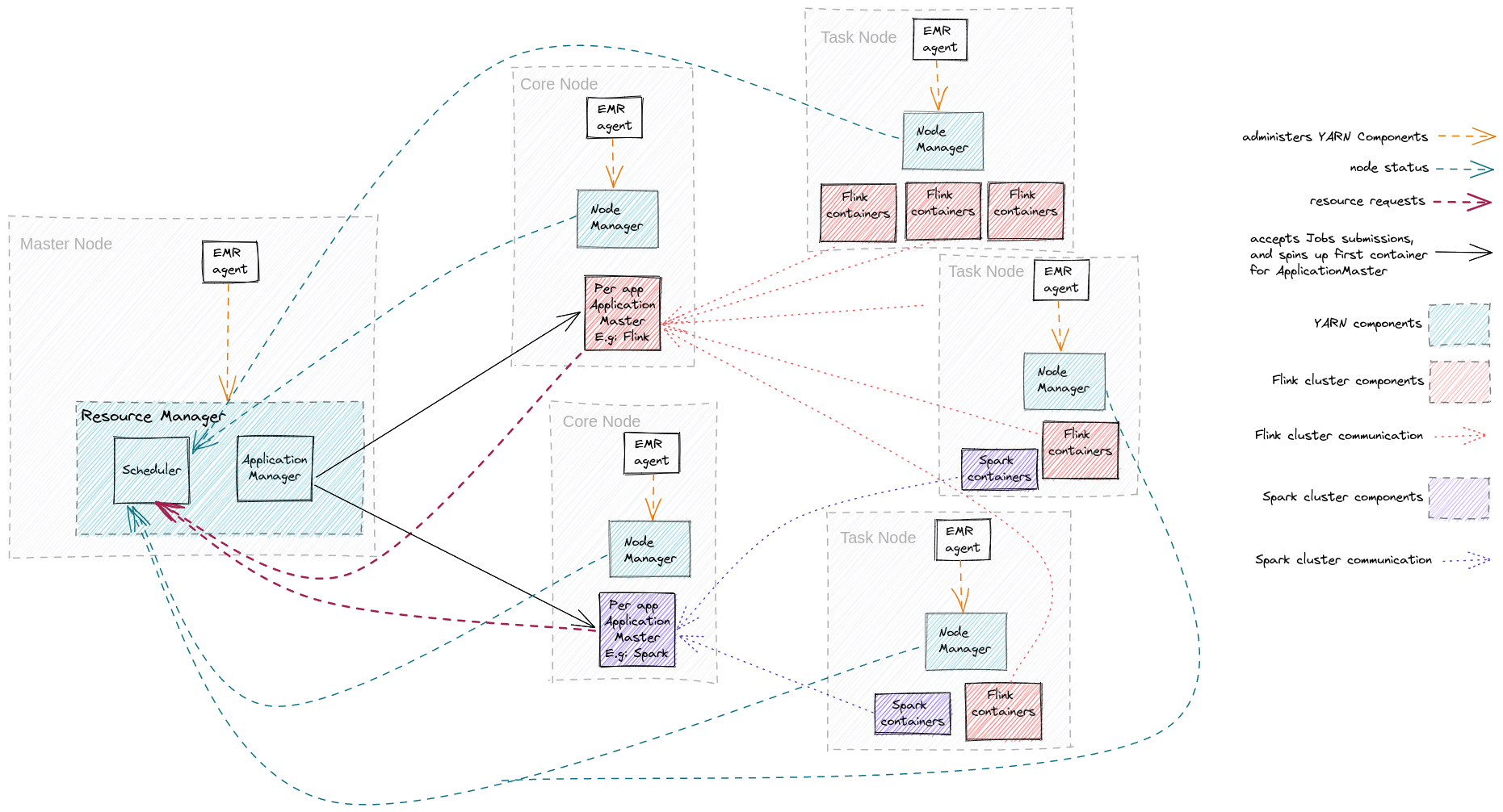
EMR Cluster nodes & YARN components
The above diagram depicts an Amazon EMR cluster with one master node, two core nodes, and three task nodes.
First, when the Cluster boots up, the EMR agent on the master node starts the ResourceManager. EMR agent is present on each node and administers all the components of YARN. It makes sure that the cluster is healthy.
Next, via AWS console or EMR API, a user requests to create two applications, one for Flink and another for Spark. YARN's ApplicationManager receives the request from the EMR agent and creates an ApplicationMaster for each application on the core nodes.
Each ApplicationMaster now requests resources from the scheduler and schedules the container on the task nodes. Core nodes may also be utilised for containers if enough free resources are available.
Each container then communicates back to ApplicationMaster for the data processing work.
Conclusion
In the realm of distributed data processing, Apache YARN is widely recognised as a resource management tool. Gaining a comprehensive understanding of its internal components enables administrators and developers to efficiently troubleshoot issues and helps in identifying performance bottlenecks.
Hope this helped, thanks for reading!