
As part of ComplyAdvantage's multi-cloud strategy, we are now on Google Cloud with GKE (Google Kubernetes Engine) as our platform of choice. This blog will walk through our team's approach to troubleshooting a particular issue we encountered with GKE. This was a unique challenge because most DNS components are managed externally with limited documentation. We hope this blog can be useful for others who may find themselves in this position!
Although there are many resources online, unfortunately, none provide in-depth explanations about how DNS operates on GKE. A solid grasp of DNS fundamentals and complexities can significantly assist in diagnosing the various causes of I/O timeouts. This blog will explain the key components of DNS resolution within GKE and provide effective strategies for troubleshooting related issues.
Problem Statement
Applications running on GKE throws Couldn't resolve server <URL> .... as DNS resolution failed for ..... The occurrence is sporadic and lacks any obvious correlation or pattern.
DNS Core Components
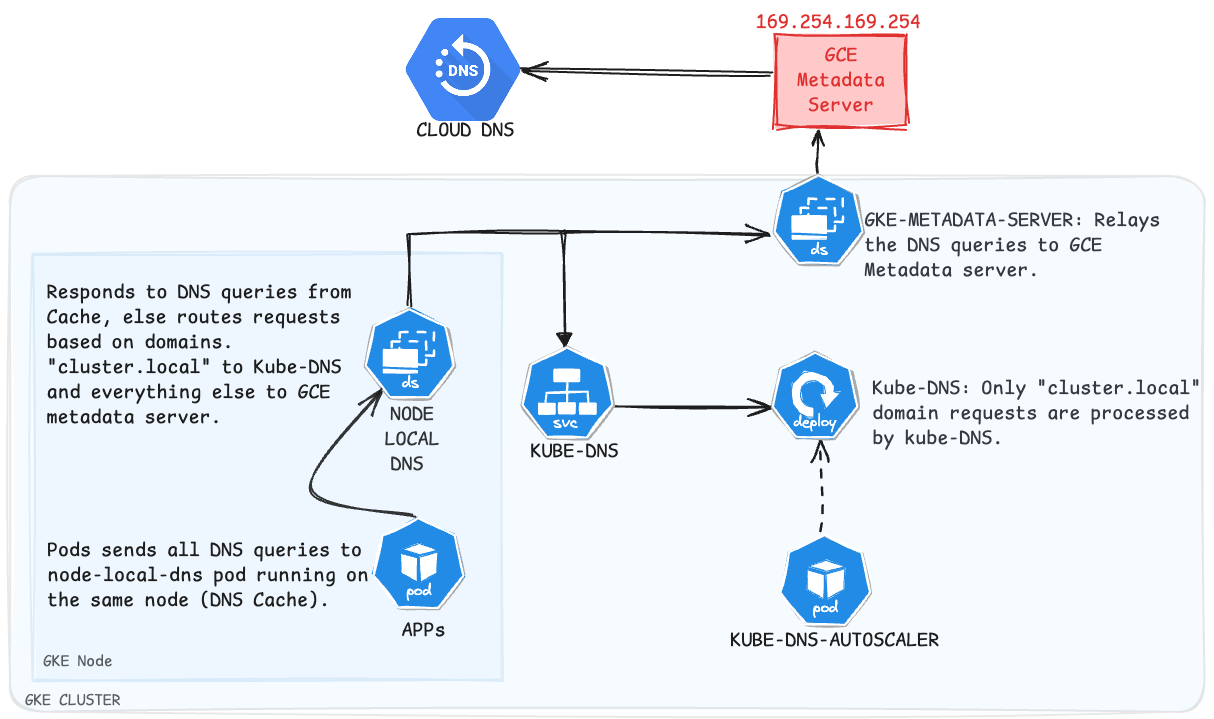
In this section, we will thoroughly examine the components listed below and explore how they interact to provide in-cluster (inside Kubernetes cluster) DNS resolution.
- KubeDNS,
- Node local DNS and
- GKE Metadata server
1. Understanding Kube-DNS
Kube-DNS is one of the popular DNS plugins in Kubernetes. Around 2018, Kube-DNS was replaced by CoreDNS. Kube-DNS uses dnsmasq - a lightweight DNS solution for small networks, to provide an in-cluster DNS solution.
Kube-DNS runs as a deployment within the Kube-system namespace and is backed by an auto-scaler. The auto-scaler looks out for the "number of nodes" and "CPU cores" within a cluster and scales Kube-DNS based on it.
It is straightforward to understand Kube-DNS, all pods in the cluster use the Kube-DNS service for DNS resolution. Based on the request's domain Kube-DNS either forwards the request to upstream DNS servers or processes itself. In GKE by default, cluster.local is resolved by Kube-DNS itself and others are sent to the Cloud DNS via the Metadata server.

Let us look at the Kube DNS Autoscaler config and how the Kube DNS is scaled. Below is the default config
{
"linear": {
"coresPerReplica": 256,
"includeUnschedulableNodes": true,
"nodesPerReplica": 16,
"preventSinglePointFailure": true
}
}
- Auto scaler polls the total number of nodes and cores in the cluster at regular intervals.
- There are two modes:
linearandladder, we will focus on linear. preventSinglePointFailure: trueguarantees that there are at least two replicas.includeUnschedulableNodes: trueauto-scaler considers un-schedulable nodes when calculating the total number of nodes in the cluster.- Scaling is done based on the formula :
replicas = max(
ceil( cores × 1 / coresPerReplica ),
ceil( nodes × 1/nodesPerReplica )
)
For example:
Cluster with 10 nodes all n2-standard-8 (8 CPU).
max(ceil(80 * 1/256), ceil(10*1/16)) = 1 replica.
However, with "preventSinglePointFailure:true", we will end up with 2 replicas
2. Understanding NodeLocal DNS
NodeLocal DNS, aka DNSCache, improves the performance of DNS resolution within the cluster by providing a local caching agent. The caching agent used by node-local-dns is CoreDNS (I will discuss CoreDNS in an upcoming blog post).
Now, let us see how NodeLocal DNS works in conjunction with Kube-DNS.
NodeLocal DNS is deployed as a DaemonSet with hostNetwork: true. Each Pod sends DNS queries to NodeLocal DNS running on the same node as the pod. NodeLocal DNS processes the request from the Cache, and if not found, forwards the request to the upstream DNS system again based on the requested domain. In GKE by default, cluster.local is resolved by Kube-DNS and others are sent to the Cloud DNS via the Metadata server.
Now that we understand how NodeLocal DNS fits in, let's take a step forward and see how NodeLocal DNS is configured.
In GKE, by default, node-local-dns runs with the below command (use command: kubectl get pod <node-local-dns-pod-name> -o yaml).
- args:
- -localip
- 169.254.20.10,10.177.0.10 # node-local-dns binds to these IP addresses which is used to listen for DNS queries
- -conf
- /etc/Corefile # the config file is explained below, is loaded from kube-system/node-local-dns config map
- -upstreamsvc
- kube-dns-upstream # service to used for upsteam
- -kubednscm
- /etc/kube-dns # kubednscm - kube dns configmap contains the configuration of kube-dns, by default its blank
Let us look at configs passed to NodeLocal DNS:
/etc/Corefileis loaded from thekube-system/node-local-dnsConfig map./etc/kube-dnsis loaded from thekube-system/kube-dnsConfigMap by default blank.
kube-system/node-local-dnsconfig map is managed by GKE andis not allowed to change. However,StubDomainsandupstream serversspecified in thekube-system/kube-dnsConfigMap can be modified to change the behavior of `NodeLocal-DNS`.Below is /etc/kube-dns . For more details, refer - NodeLocal-DNS config
# node-local-dns listens for the DNS requests
# with domain (cluster.local) at address port(53).
cluster.local:53 {
# enables logging in case of DNS errors
errors
# defines AAAA DNS queries are response by node-local-DNS
template ANY AAAA {
# response code for these queries will always be successful.
# TL;DR
# NOERROR is returned if the requested domain
# name is present within the DNS tree, no
# matter if the requested DNS Record Type
# exists. Alternatively the status might
# appear as NODATA, when the response code
# is NOERROR and no RR are set
rcode NOERROR
}
# this bit is most important, caches DNS request to
# improve DNS performance.
# If you are curious, runs some DNS performance test
# (using tools like "dnsperf") by altering directives config.
cache {
# TTL, all successful responses will be
# cached for max 9984 secondsand min of 30.
success 9984 30
# TTL, negative(denial) responses will
# be cached for 9984 or 5 mints.
denial 9984 5
}
# enables automatic reloading of the DNS
# configuration when changes are detected.
reload
# ensuring that DNS quries are not caught in infinite loops
loop
# Bind the DNS server with the IP address,
# in this case 10.177.0.10 is the kube-dns svc
# clusterIP, 169.254.20.10 is the dummy link local
# address created by node-local-dns.
bind 169.254.20.10 10.177.0.10
# healthcheck endpoint for the DNS server
health 169.254.20.10:8080
# node-local dns act as proxy and forward all the
# matching request to other DNS server - PILLAR__CLUSTER__DNS
# placeholder: 10.177.20.229 - IP address of
# kube-system-upstream svc
forward . __PILLAR__CLUSTER__DNS__ {
# uses TCP for DNS resolution
force_tcp
# unused connection in the connection pool
# cleaned up every 1 sec
expire 1s
}
# DNS server to exposes prometheus metrics at port 9253
prometheus :9253
}
# this is catch all rule.
.:53 {
errors # same as above
template ANY AAAA { # same as above
rcode NOERROR # same as above
}
cache 30 # same as above
reload # same as above
loop # same as above
bind 169.254.20.10 10.177.0.10 # same as above
# node-local-dns at as a proxy and forwards
# all the matching request to other DNS server -
# PILLAR_UPSTREAM_SERVERS: /etc/resolv.conf of the node
# Configured to GKE metadata server: 164.259.164.259
forward . __PILLAR__UPSTREAM__SERVERS__
prometheus :9253 # same as above
}
NodeLocal DNS has multiple variables. These variables are evaluated by NodeLocal DNS based on all the config passed:
__PILLAR__DNS__SERVER__: Kube-DNS service IP - something like 10.177.0.10__PILLAR__LOCAL__DNS__: static link-local IP - 169.254.20.10__PILLAR__DNS__DOMAIN__: cluster domain - by default cluster.local__PILLAR__CLUSTER__DNS__: upstream server for in-cluster queries - kube-dns-upstream svc IP: 10.177.20.229.__PILLAR__UPSTREAM__SERVERS__: upstream servers for external queries. Metadata server IP: 169.254.169.254
kube-system/kube-dns config map for the upstream server.Further read about NodeLocal DNS variables: https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/#configuration
3. Understanding GKE Metadata Server
The GKE Metadata server contains subsets of information from the GCE(Google Compute Engine) Metadata server which is essential for GKE. It is deployed as a DaemonSets when the ID federation is turned on.
The GKE Metadata Server intercepts all the requests going to the GCE Metadata Server at http://metadata.google.internal (169.254.169.154:80). Further read https://cloud.google.com/kubernetes-engine/docs/how-to/workload-identity
In a Nutshell, how everything comes together
- Node-local-DNS is launched as a daemon set with Host Network (hence, it uses the same network namespace as the node and has access to all network components of the nodes) and thus manages the IPtables rules of the nodes.
# Validate pods running on HostNetwork mode:
$ kubectl get po <node-local-dns-pod-name> -n kube-system -o yaml | grep -i hostnetwork
## output
# hostNetwork: true
- Node-local-DNS listens on every GKE node on the IP addresses
169.254.20.10 and 10.177.0.10on port 53. To Validate, SSH into one of the GKE nodes
# Validate there's a dedicated interface for nodelocaldns and listening at correct IP
$ ip addr show nodelocaldns
## OUTPUT
# nodelocaldns: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
# link/ether 72:8e:e9:83:5f:8e brd ff:ff:ff:ff:ff:ff
# inet 169.254.20.10/32 scope global nodelocaldns
# valid_lft forever preferred_lft forever
# inet 10.177.0.10/32 scope global nodelocaldns
# valid_lft forever preferred_lft forever
# Validate the IP tables rules in Input and Output chain in filter(defualt) table
# As mentioned above these are node-local-dns pods modifying the nodes IP tables to whitelist these DNS connections
# Below rules allows incoming/outgoing DNS request at port 53
sudo iptables -L
## OUTPUT
Chain INPUT (policy DROP)
target prot opt source destination
ACCEPT udp -- anywhere 10.177.0.10 udp dpt:domain /* NodeLocal DNS Cache: allow DNS traffic */
ACCEPT tcp -- anywhere 10.177.0.10 tcp dpt:domain /* NodeLocal DNS Cache: allow DNS traffic */
ACCEPT udp -- anywhere 169.254.20.10 udp dpt:domain /* NodeLocal DNS Cache: allow DNS traffic */
ACCEPT tcp -- anywhere 169.254.20.10 tcp dpt:domain /* NodeLocal DNS Cache: allow DNS traffic */
Chain OUTPUT (policy DROP)
target prot opt source destination
ACCEPT udp -- 10.177.0.10 anywhere udp spt:domain /* NodeLocal DNS Cache: allow DNS traffic */
ACCEPT tcp -- 10.177.0.10 anywhere tcp spt:domain /* NodeLocal DNS Cache: allow DNS traffic */
ACCEPT udp -- 169.254.20.10 anywhere udp spt:domain /* NodeLocal DNS Cache: allow DNS traffic */
ACCEPT tcp -- 169.254.20.10 anywhere tcp spt:domain /* NodeLocal DNS Cache: allow DNS traffic */
- Node-local-DNS adds NOTRACK rules for connections to and from the node-local DNS IP. Further read https://github.com/kubernetes/enhancements/blob/master/keps/sig-network/1024-nodelocal-cache-dns/README.md#iptables-notrack
# Validate the NOTRACK rules in the raw IP table
sudo iptables -t raw -L
## OUTPUT
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
CT udp -- anywhere 10.177.0.10 udp dpt:domain /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT tcp -- anywhere 10.177.0.10 tcp dpt:domain /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT udp -- anywhere 169.254.20.10 udp dpt:domain /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT tcp -- anywhere 169.254.20.10 tcp dpt:domain /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
CT tcp -- 10.177.0.10 anywhere tcp spt:http-alt /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT tcp -- anywhere 10.177.0.10 tcp dpt:http-alt /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT udp -- anywhere 10.177.0.10 udp dpt:domain /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT tcp -- anywhere 10.177.0.10 tcp dpt:domain /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT udp -- 10.177.0.10 anywhere udp spt:domain /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT tcp -- 10.177.0.10 anywhere tcp spt:domain /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT tcp -- 169.254.20.10 anywhere tcp spt:http-alt /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT tcp -- anywhere 169.254.20.10 tcp dpt:http-alt /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT udp -- anywhere 169.254.20.10 udp dpt:domain /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT tcp -- anywhere 169.254.20.10 tcp dpt:domain /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT udp -- 169.254.20.10 anywhere udp spt:domain /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
CT tcp -- 169.254.20.10 anywhere tcp spt:domain /* NodeLocal DNS Cache: skip conntrack */ NOTRACK
- With these IPtables rules in place, all DNS requests from the pods can now be locally consumed by
node-local-dnspods. - Node-local-DNS forwards the DNS queries to upstream DNS servers based on the configs in
/etc/Corefile. Allcluster.localwould be forwarded to kube-DNS (via kube-dns-upstream service - 10.177.31.30) and others would be tometadata.server- 169.254.169.254
Identify the Issue
As we've seen everything starts from Node-local-DNS, look for i/o timeout in the log of node-local-dns pods.
kubectl logs <node-local-DNS pod name> | grep -i "i/o timeout"
Issue-1: Timeout from the Kube DNS
When the log line contains <node IP/node-local-dns IP>:<port-number>->10.177.20.229:53 : i/o timeout. This indicates that the in-cluster DNS plugin is failing. Example logs below:
2024-03-11 12:00:39.203
[ERROR] plugin/errors: 2 nexus.test1.cluster.local A: read udp 10.177.32.107:59938->10.177.22.204:53: i/o timeout
Issue-2: Timeout from GKE metadata server
When the logs line contains <node IP/node-local-dns IP>:<port-number>->169.254.169.254:53 : i/o timeout. This indicates that external DNS resolution is failing. Example logs below:
2024-03-11 12:00:39.203
[ERROR] plugin/errors: 2 nexus.company.in. A: read udp 10.177.32.107:59938->169.254.169.254:53: i/o timeout
Solutions
How to solve Issue-1: timeout from the Kube DNS?
The first and foremost question is, why does Kube DNS time out when it's backed by auto-scaler?
To answer this question we need to go back to our node-local-cache config, which forwards DNS requests to kube-dns for cluster.local:53 domain. As you see, the connection forces TCP connections, and the ideal TCP connection expires in a second. Due to this when lots of DNS queries are made by different workloads, node-local-dns just creates new TCP connections without any upper bound. On the other hand, Kube-dns have a hard-coded limit on the TCP connections, which is 20. Each connection creates a new dnsmasq process in a dnsmasq container in the Kube DNS pod.
To overcome this we need to scale the number of replicas of the Kube DNS by altering the KubeDNS Autoscaler config.
Let's tweak the value of coresPerReplica and nodePerReplica, and add in min and max and run through the same example we've seen before:
{
"linear": {
"min": 4,
"max": 100,
"coresPerReplica": 10,
"includeUnschedulableNodes": true,
"nodesPerReplica": 2,
"preventSinglePointFailure": true
}
}
Same example cluster with updated config
Cluster with 10 nodes all n2-standard-8 (8 CPU).
max(ceil(80 * 1/10), ceil(10*1/2)) , => max(8,5) =>8 replica.
Generally, this solves 99% of the use cases. Suppose you’re still having issues after scaling kube-dns, it's probably time to move on to CoreDNS(Note Google does not provide you with coreDNS at least at the time of writing, so it's something you need to manage. This includes routing traffic from node-local-dns to coreDNS, deploying, configuring, and scaling CoreDNS) or Cloud DNS.
How to solve Issue-2: timeout from the GKE Metadata Server?
This situation is tricky as Google does not provide much information about it. We’re now left with two options:
- Debugging your GKE environment independently or with the assistance of Google Support, if available.
- Deploying a custom DNS resolver.
In ComplyAdvantage, we’ve used global DNS servers 8.8.8.8 and 1.1.1.1. This works fine as all of our DNS zones are public.
In GKE, as we've seen before, editing of kube-system/node-local-dns ConfigMap is not allowed. However, as we’ve seen previously node-local-dns takes in parameters from kube-system/kube-dns and updates its rules. Let us add upstream global DNS servers.
data:
stubDomains: |
{
"internal": [
"169.254.169.254"
]
}
upstreamNameservers: |
[
"8.8.8.8",
"8.8.4.4",
"1.1.1.1"
]
With the above config,
cluster.localdomain DNS queries would then be forwarded to the Kube-DNS,internaldomain requests to GCE metadata server - 169.254.169.254,- and everything else goes to the upstream DNS server.
Hopefully, this will be handy while troubleshooting any in-cluster DNS timeout issue.