The Problem
Any sanctioned person screening system needs to be able to consider inexact ("fuzzy") name matches - transliteration errors, OCR issues, and subterfuge can pop up at any time. Unfortunately, surfacing relevant inexact name matches also raises the possibility of surfacing irrelevant matches, wasting analysts' time. Trading off the number of relevant vs irrelevant matches produced by a name search algorithm is always a challenge.
“Under the hood”, one of the reasons for this challenge is that many techniques for fuzzily matching names group them into broad buckets, limiting the degree of control we have over the trade off.
The Solution - Name Embeddings
If we had some way to precisely and numerically compare names (e.g. “John” and “Jon” have a similarity of 2.29), we could more precisely trade off the rate of relevant vs irrelevant name matches. Such a technique could also generalise to learn additional name matches that existing rule-based approaches struggle with.
To that end, we’ve investigated name embeddings - a promising approach for providing precise, numerical and fast name similarity scores. This blog post outlines our approach, and the benefits name embeddings provide.
The Solution Space - How Can We Match Names?
A core part of an effective name search algorithm is the capacity to make fuzzy matches between names that are not exactly the same – for example:
“john smirnoff” vs “jonathan smirnof”
At a word level, there are several methods for doing this:
- Edit Distance (a term which can apply to various algorithms - this post focuses on Damerau-Levenshtein) – count the number of character insertions, deletions, substitutions and transpositions required to change one word into the other. Match words that have a small edit distance between them (e.g. only match words which are one change apart).
- Phonetics – Match words that sound similar using one of a number of phonetic algorithms (Soundex, Double Metaphone, NYSIIS, etc.).
- Equivalent Names Lists – Match words that are on a predefined list of equivalent nicknames and spellings.
- Hashing – Compress words down to a spelling-dependent key & match other words with the same key/ set of keys. Includes many character N-gram based techniques.
- Word Embeddings – Convert each word into a vector. Search for its neighbours in vector space, and match with words that have similar vectors.
| Base Word | Linked Word | Match Type | Linked On: |
|---|---|---|---|
| John | Jon | Edit Distance 1 | Edit Distance 1 Change: Jon + 1 x (Insert “h”) = John |
| John | Juan | Phonetic Match | Shared Double Metaphone Code: “JN” |
| John | Jonathan | Equivalent Name | Both on a Predefined Equivalent Name List: John = Jonathan, Jon, Jonni, … |
| John | Johnny | Hashing Match | Shared Letter Triplets: “joh”, “ohn” |
| John | João | Embedding Match | Nearby Vectors: John = [1,0,3,4] & João = [1,0,2,3] |
The Coarse Trade Offs of Existing Approaches
The key trade off of any name matching system is “good matches made” (recall) vs “bad matches made” (noise). If you make your fuzzy matching rules "a wider net" to catch more matches of concern, they also let through more spurious matches.
Consider the following set of words, “chris”, “cris”, “kris”, “maris”, “chaos”, and “hcrsi”:

Consider a case where we only want to match “chris” and “cris” . We could simply say that any two words that are within a (Damerau-Levenshtein) edit distance of 1 should match, which would only group those two:

However, if we wanted to cast a slightly broader net and use edit distance to group “chris”, “cris” and “kris”, we would have to allow an edit distance of 2 in response. In doing so, we would find that “chris” matches every single one of the words above! I.e.
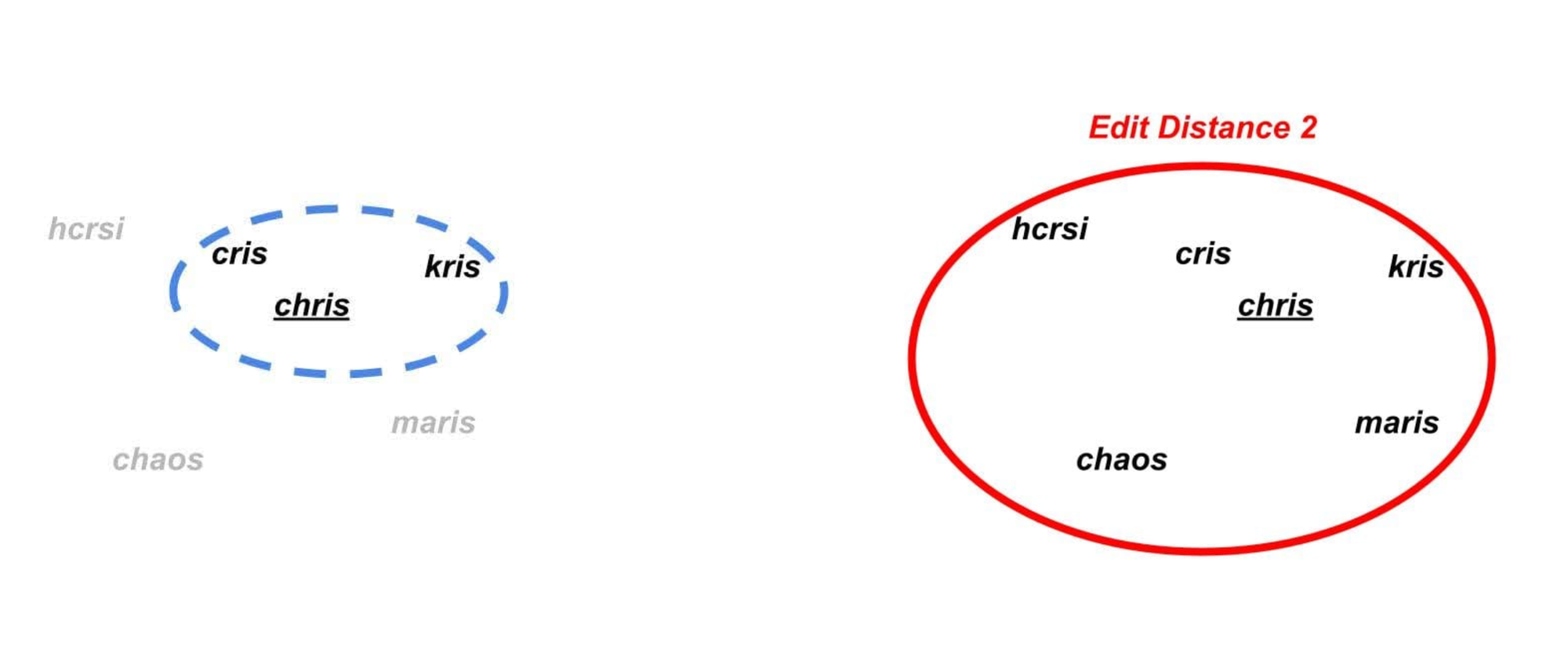
As words like “chaos” are unlikely to be a relevant match to “chris”, expanding our fuzzy matching system has allowed through significant additional noise. The problem we have run into with the example above is that, for a given fuzzy matching technique, we can struggle to distinguish a “good” match from a “bad” one – to an edit distance-based matching system, “kris” and “chaos” are both equivalent edit distance 2 matches to “chris”. This is especially problematic because there are tens of thousands of 5-letter words within an edit distance 2 from “chris”, most of which are not equivalent names.
While we can somewhat mitigate this problem by combining the techniques above (e.g. a match that is both phonetic & edit distance 1 is better than one that is merely edit distance 1), it would be ideal to have a technique that directly measures how similar two words are with a greater degree of precision.
Word Embeddings to the Rescue
Embedding words is a solution to this problem. By assigning each word a vector (a series of numbers - e.g. [-4, 5, 2, 7]), we can represent words numerically & so measure the distance between them precisely. This has a number of other useful properties - for example, searching for similar vectors is a relatively efficient operation that scales well with dataset size.
Embedding words is often done with a trained machine learning model, that takes in a word and outputs a corresponding vector. There is an infinite number of possible ways to embed words - different training goals, training data, embedding model architectures and distance measurements will all lead to different embeddings.
Our goal was to train a word embedding model such that the distance between the embedding of “john” and the embedding of “jonathan” measures directly the similarity between the two names. Such an approach holds promise for fuzzily matching names against large datasets, because it's simple to tune the “good matches made” vs “bad matches made” trade off, and is efficient to implement.
Semantic Embeddings are Not Enough
We cannot discuss the concept of word embeddings without touching on semantic embeddings. Semantic embedding is a well-studied field that underpins all modern large language models, that assigns vectors for words based on their usage in text. These embeddings have been found to effectively encompass the “meaning” of the words:
Unfortunately for us, semantic embedding models do not work well at picking up name variants. Names don't have meaning in quite the same sense that regular English words do, and can be infrequent in the large corpora of text that semantic embedding models are trained on. This leads semantic embedding models like FastText to struggle to match similarly spelled names. This is clearly shown in our internal tests, measuring the capacity of various embedding models to group equivalent names from a list of sanctioned person aliases without also including clearly unrelated names:
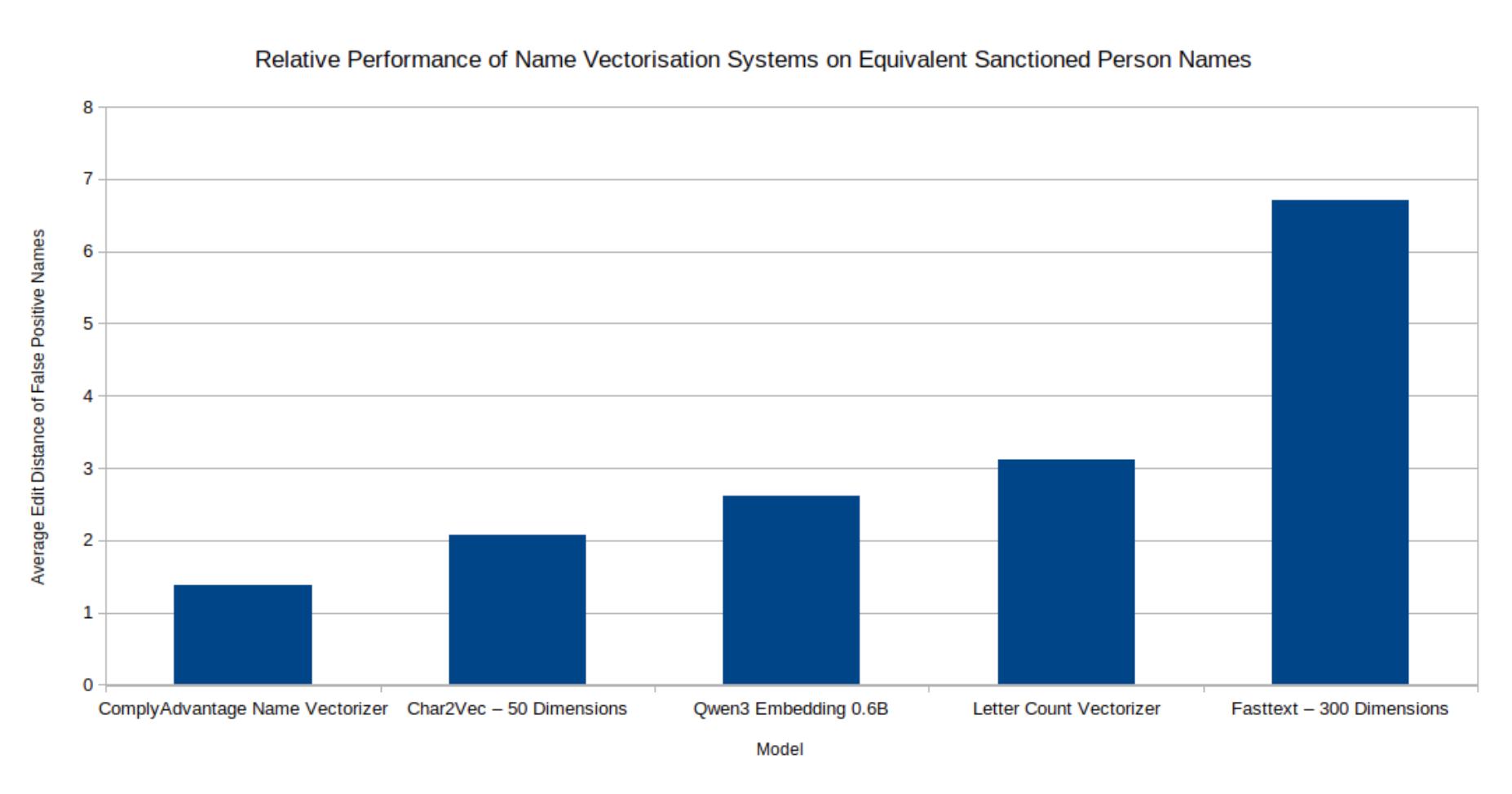
Equivalent Name Embedding Models
These limitations push us to focus on a different class of models – equivalent name embeddings. Inspired by semantic embedding models, we have trained a transformer-based model directly on the task of grouping equivalent names. As "equivalent" is an ambiguous term, we defined our goal as being able to group names that look and sound similar (as opposed to nicknames etc). Training data on equivalent names is hard to come by, but we were able to leverage our internal experience in entity resolution and our large database of risk-associated individuals to create a large dataset of millions of similar looking & sounding names for this purpose.
Example Training Name Pairs:
| Name 1 | Name 2 |
|---|---|
| vladimir | vladymyr |
| mckay | mckaeigh |
| sheryl | cheryl |
Name Embedding Architecture
To turn a name into an embedding, we first break it down into components or "tokens". Multiple tokenisation schemes are possible, and we chose to break names down into their component letters, which were each given their own embedding. This series of letter embeddings was then fed into a 100,000 parameter, transformer-based model to produce a word embedding.
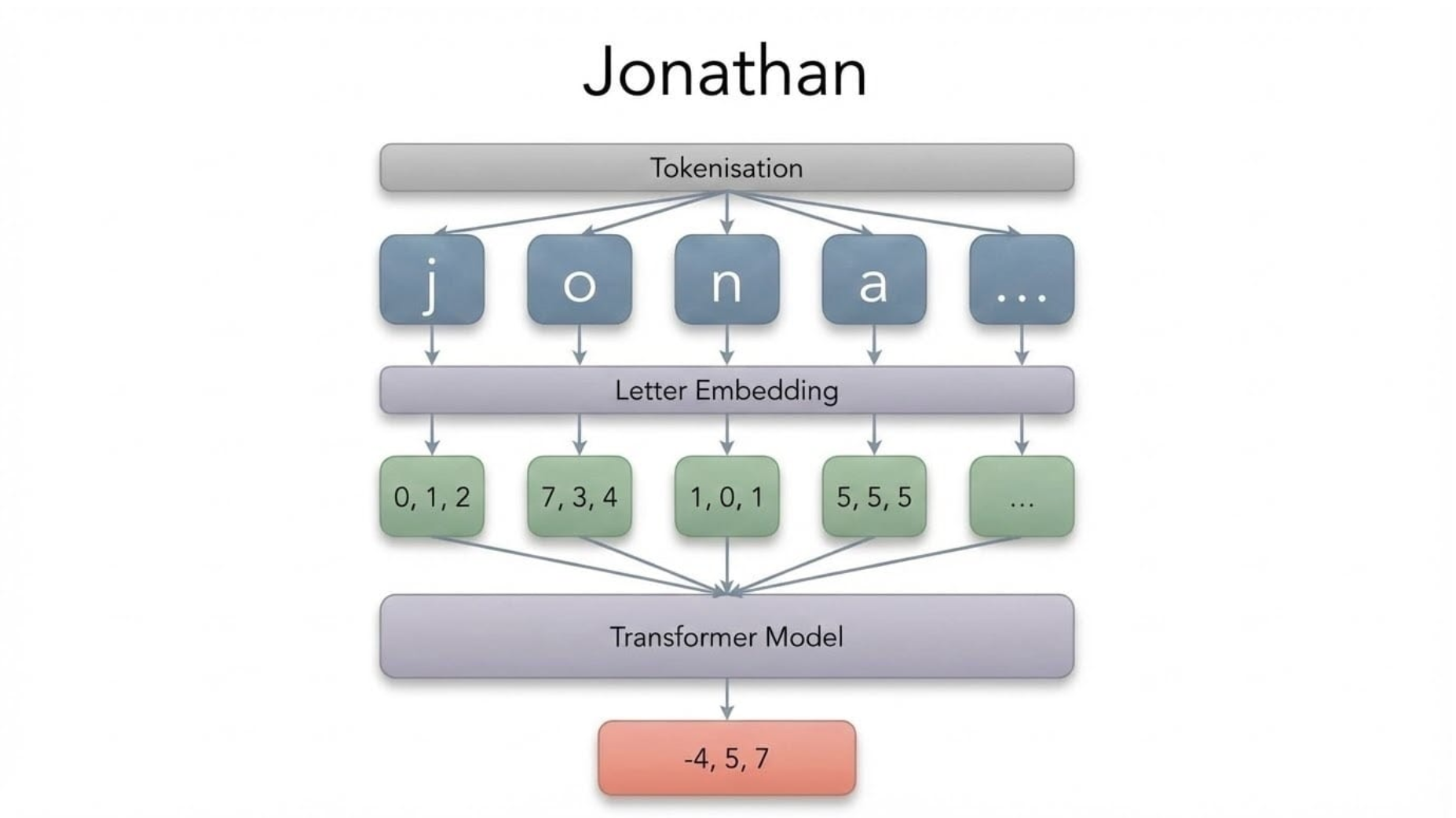
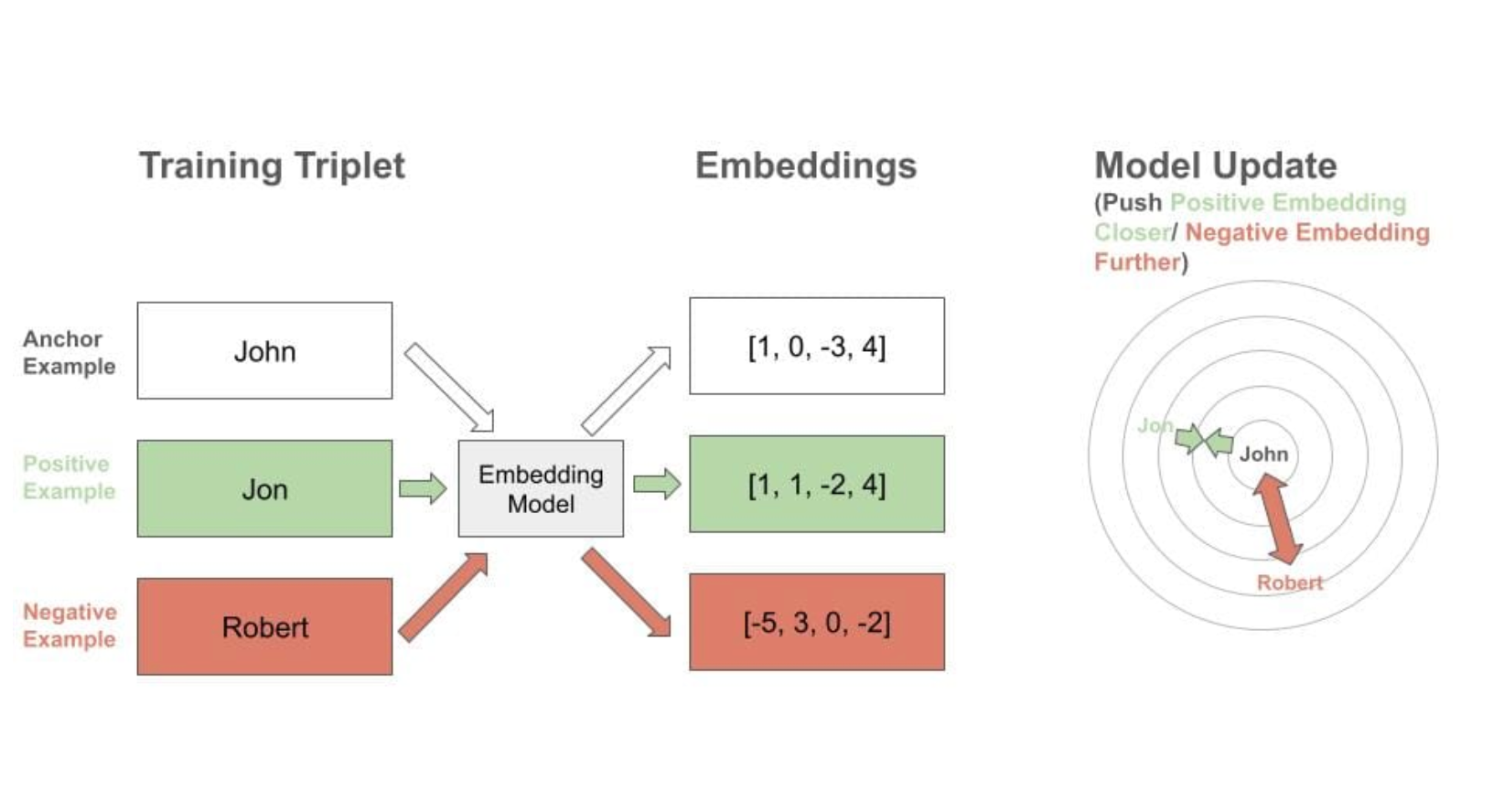
Of course, a name embedding is only useful if similar names are given similar embeddings. To ensure this, a triplet loss based training scheme was used - the model is presented with an “anchor” example name, and matching "positive" name, and a mismatching "negative" name. The embeddings of each are calculated, and then adjusted to move the anchor and "positive" name embeddings closer together, and the anchor and "negative" name embeddings further apart.
The architecture we found to work best was a combination of character and position embeddings, passed into a transformer encoder & several dense layers, to produce an output 16-dimensional embedding. The training schedule proved to be as important as the exact architecture - exposing the model to "hard" training examples it found confusing proved key to achieving good performance.
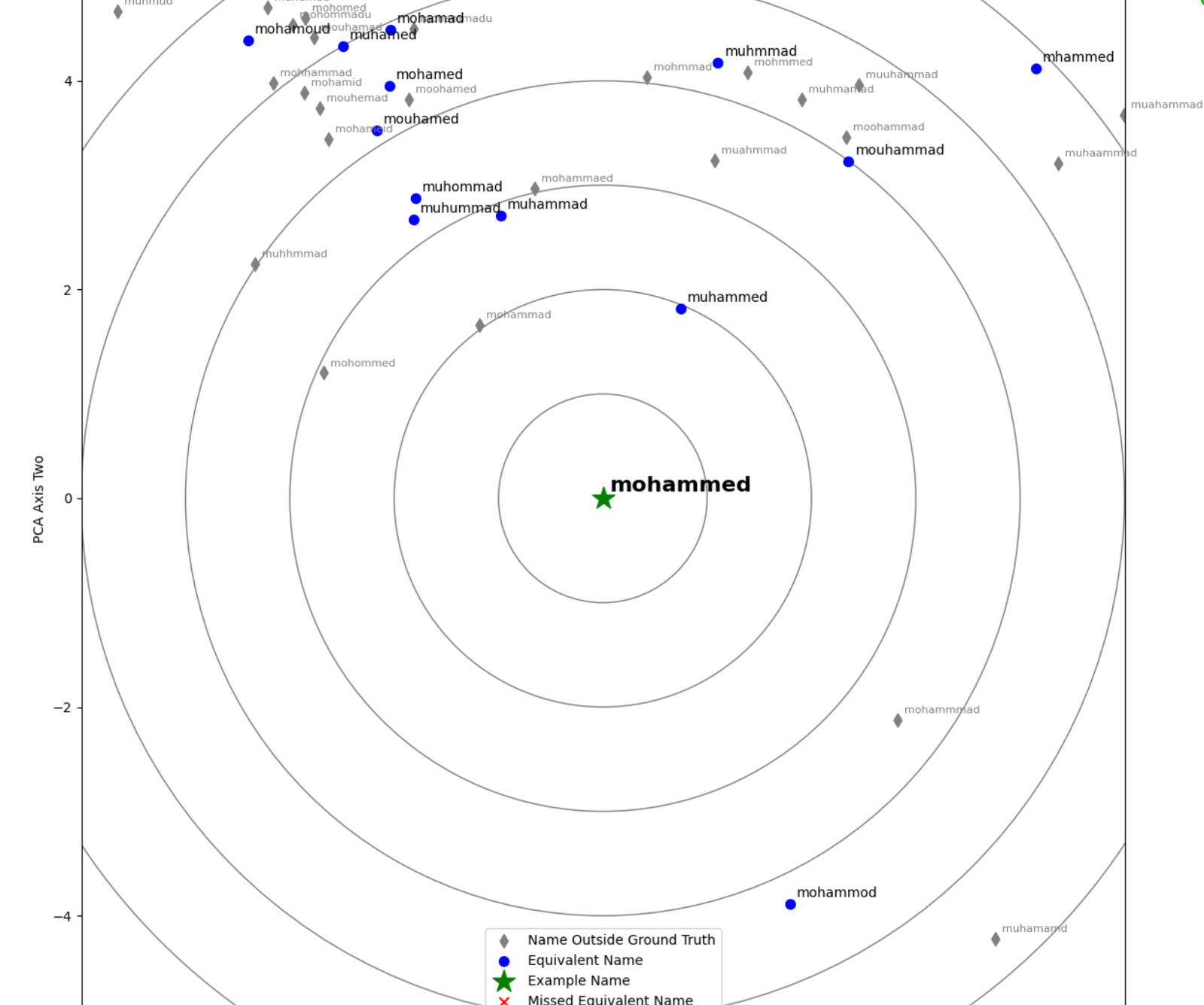
Name Embedding Examples
Being trained on hundreds of thousands of example training triplets, our model has learned to group similar names into nearby areas of the vector space. Using the Hierarchical Navigable Small Worlds clustering algorithm (as implemented by FAISS), we are able to rapidly and efficiently define these clusters of similar names. These are visualised with the nearest neighbour “radar” diagrams below, in which example names are compared to their nearest neighbours in dataset of sanctioned individuals’ names.
The actual vector space has a much higher number of dimensions, but has been compressed down to 2D for ease of visualisation. Nearest neighbours are defined according to L2 Euclidean distance, and this distance between the example word and its nearest neighbours in the vector space has been preserved in the 2D transformation.

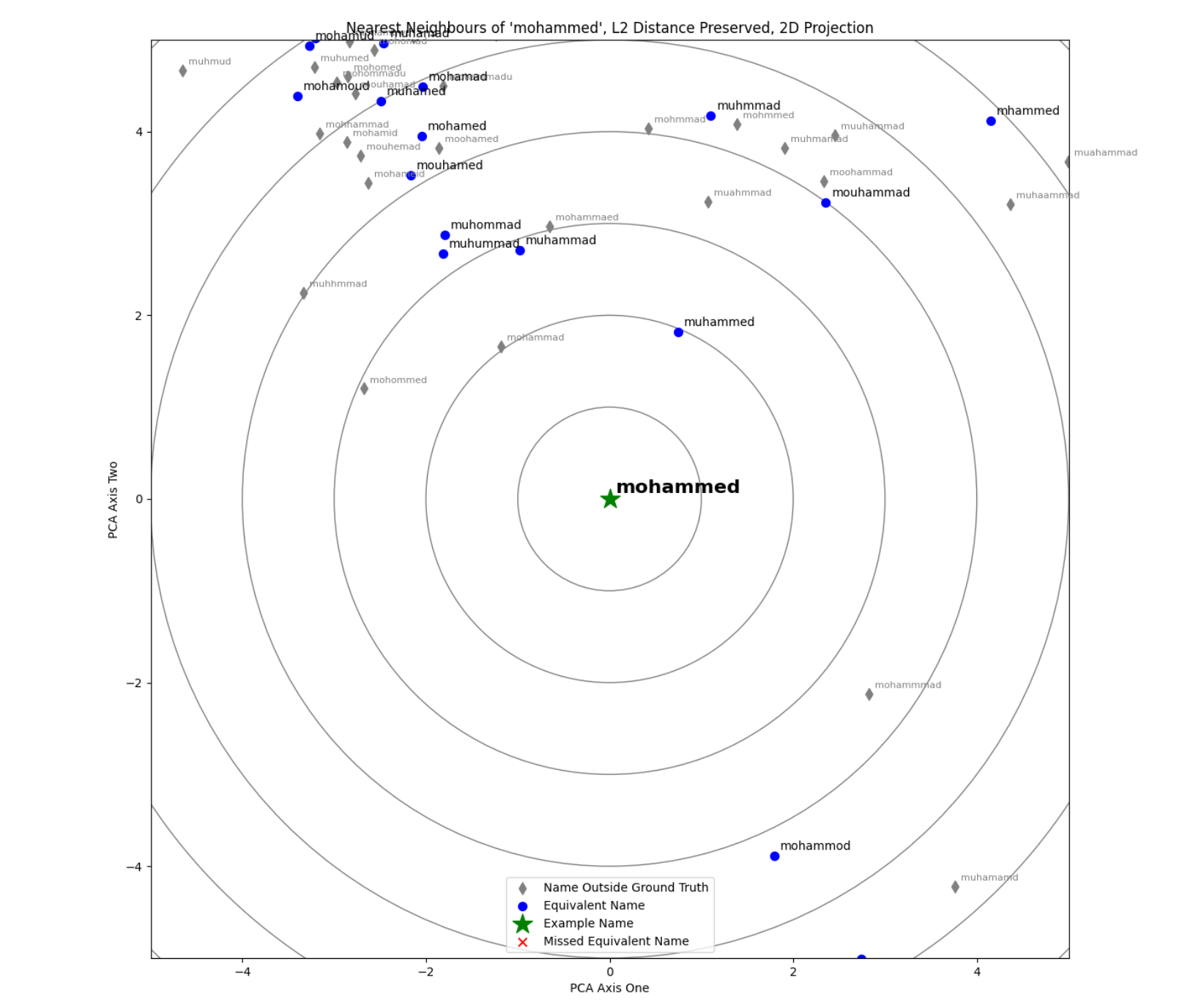
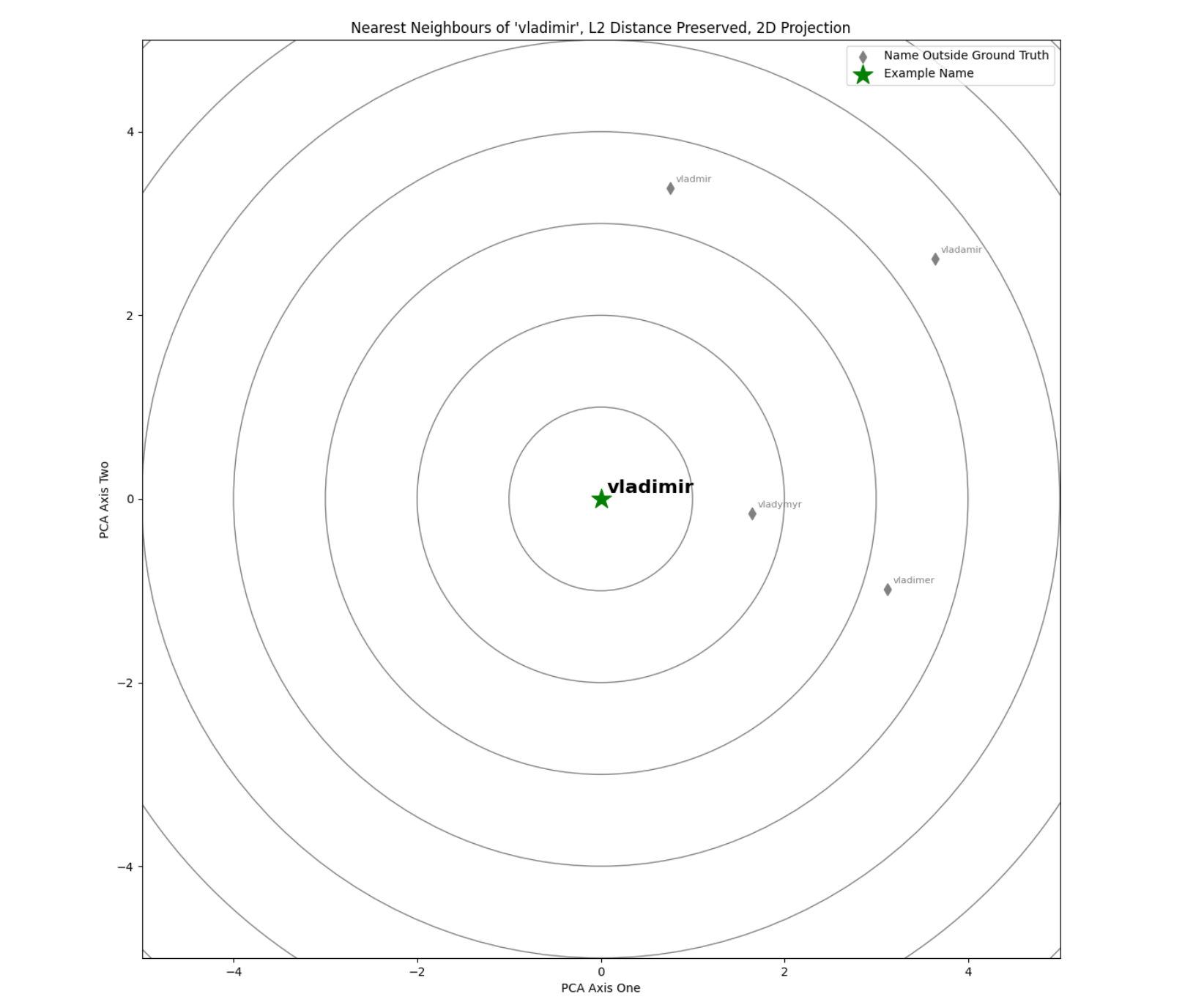
These allow us to make more intelligent fuzzy matches, linking words that are spelled distinctly and are not viewed as phonetic matches, but which humans still view as similar/equivalent:
| Word 1 | Word 2 | L2 Euclidean Distance in Vector Space |
|---|---|---|
| mouhamed | muhmmad | 4.7 |
| kobaishi | kubaysi | 4.6 |
| alsugayer | alsughair | 4.6 |
| icaevich | isaievych | 4.2 |
| viaceslav | vyacheclav | 3.6 |
Example Real Sanctioned Name Variants Caught by Vector Matching, that Other Fuzzy Matching Techniques Struggle to Catch
Performance
These name embeddings are only useful if they simultaneously allow us to
- Link additional relevant names
- Avoid linking a large number of additional irrelevant names
By moving the cutoff above which we disregard hits (e.g. disregarding names that are further than distance 8.25 from each other), we can directly and precisely trade off between maximising relevant and minimising irrelevant hits. After some tuning, we found a threshold that provided a good balance, allowing us to:
- Link 88% of the sanctioned name pairs on an internal test dataset of difficult to match sanctioned names (that are currently covered by equivalent names lists)
- At the cost of a mere 5% jump in false positives on a dataset of production-like searches
This compares favourably to rival fuzzy matching approaches such as edit distance 2, which would only have been able to catch 59% of the difficult to match sanctioned name pairs (and with far less capacity to precisely trade off extra recall against extra false positives).
Why Not Equivalent Name Lists?
Seeing the pairs of equivalent names above does raise a question – why not just add them to an equivalent names list and not bother with a model? It is a fair question to ask – basically, any match you desire could be caught by continually updating a giant list of equivalent names. However, equivalent names lists have two clear downsides:
- An equivalent names list is innately reactive – if you have not seen a pair of names before, there’s no way you can match them. This is certainly not ideal for a sanctions screening system. Name embedding models can automatically detect similar names without any human intervention & without having seen either of the names before.
- Beyond that, it is very expensive to have humans look through potentially millions of name pairs & decide which should be viewed as equivalent.
Summary
In summary, name embeddings are a promising technique for fuzzy matching, utilising approaches inspired by the latest advances in large language model research. They enable us to:
- Trade off the relevant name match vs irrelevant name match ratio more precisely than was previously possible.
- Make word-to-word matches that legacy approaches may struggle with.
- Perform very fuzzy matching with lower latency than existing approaches, by leveraging the latest vector databases & approximate nearest neighbours search algorithms.
- Make sanctions screening tools more robust to new & potentially deliberately introduced name variants.