
Problem statement
In distributed applications, duplicate entries aren't just a simple nuisance; they can be a critical failure that can corrupt data and break user flows. We’ve encountered this challenge while implementing a multi-step, gRPC-based flow.
Our specific challenge centred on a single, critical synchronous step. This step, invoked via gRPC, blocks all others and contains a heavy multi-table operation on our distributed database to both create an entry and check for its uniqueness. As concurrent requests increased, we needed a way to check for duplicates fast without having to rely on the database integrity check which would significantly increase the execution time.
Saga and reservation patterns
To overcome the aforementioned issue, a saga pattern can be employed, relying on a reservation pattern to manage the critical first step.
A saga is a pattern for managing data consistency in distributed systems by substituting expensive distributed transactions with a sequence of local transactions.
The reservation pattern works similarly to an application-level lock, where the application denotes its intent to reserve a set of data and has a specific time limit to complete its operation.
Adapting the flow
Applying this combined pattern requires two significant changes to the flow.
First, the critical synchronous step needs to be refactored to extract the minimal data required to uniquely identify a request, called “intent”.
Second, a new, lightweight service—a Reservation Management System (RMS)—is introduced. This service is responsible for performing the rapid idempotency check using only that "intent" data. To manage these short-lived reservation "locks" at high speed and scale, the RMS must be backed by a fast, shared-state, in-memory data store. Redis is a canonical choice for this role.
This refactoring fundamentally changes the flow's logic. The reservation of the “intent” becomes the new and only critical, synchronous step, acting as the fast "fail-fast" gate for idempotency.
The worker that handles the gRPC request acts as the Saga Orchestrator, which is responsible for:
- Reserving the "intent" via the RMS. This is the crucial step; its success starts the saga.
- Orchestrating the remaining steps in the workflow.
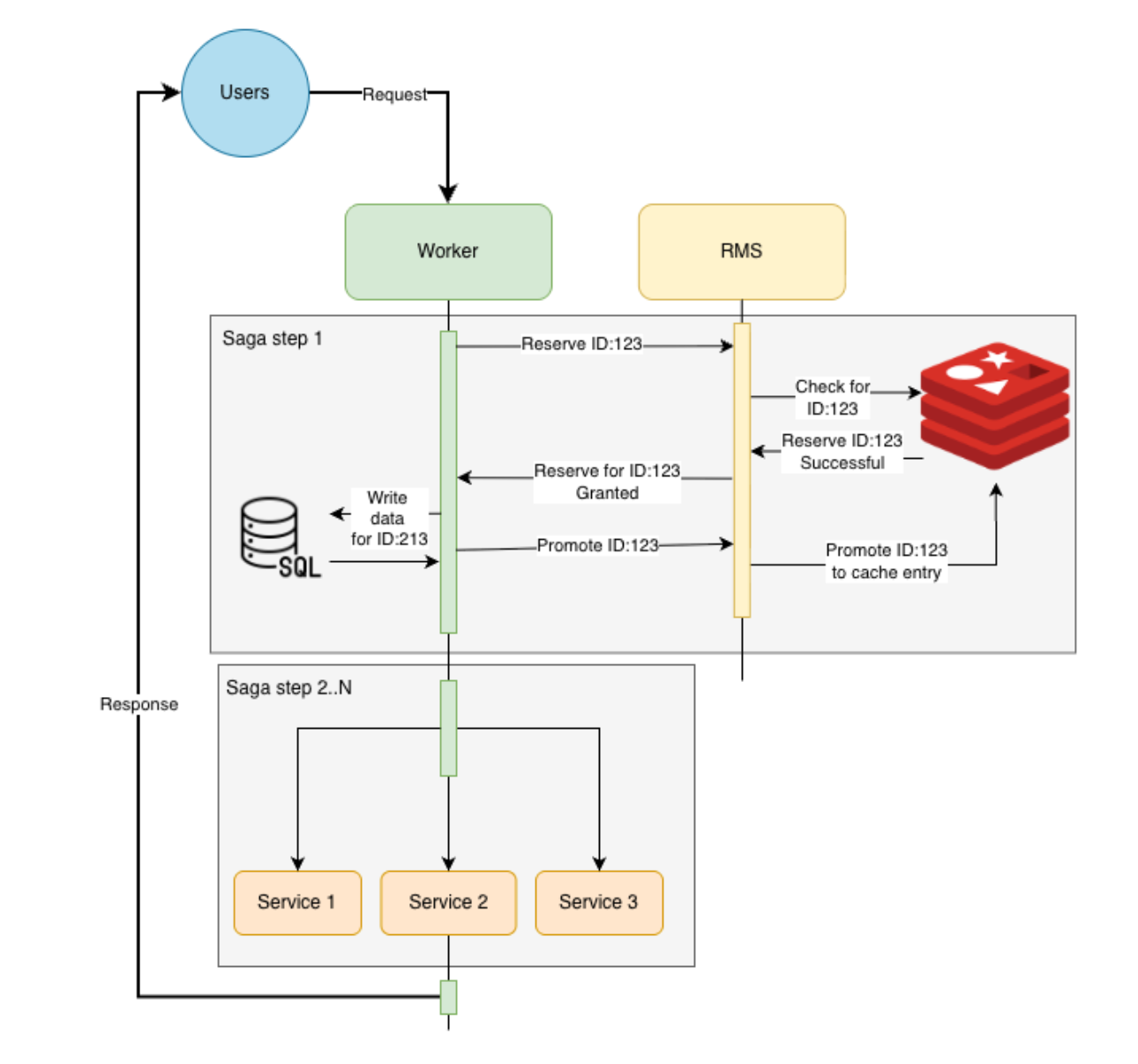
Once this reservation is secured, the original, heavy multi-table operation can proceed (e.g., asynchronously). Crucially, if this subsequent database operation fails, the flow is not reverted. Instead, a compensating transaction can be queued to handle the failure—fulfilling the saga pattern—while the initial reservation has already guaranteed uniqueness.
The following sections assume that Redis is being used as the building block of the RMS and a SQL database as the main storage.
Step 1: Reserving the intent
The worker (Saga Orchestrator) generates a unique session_id. It then issues a request to the RMS to register the "intent."
{
"session_id": <generated_session_id>,
"reserved_value": <intent_data>
}
The RMS must perform the following logic:
- Generate a unique fencing token: Upon receiving the request, generate a secure unique token for this specific lock attempt.
- Atomically attempt to acquire the lock: The RMS combines the session_id with the fencing token and attempts to set the key:
SET processing:<intent_data> "<session_id>:<fencing_token>" NX EX <expiration_window>
Note: The NX is an option that guarantees the lock only if the value does not exist, while the EX sets a lease for the value.
- Analyse the SET result:
- If the SET command fails (returns nil): A lock for the intent_data already exists, the request is a concurrent operation and the RMS immediately returns a “Conflict” failure.
- If the SET command succeeds: The RMS has acquired the lock. It must now check if there is a duplicate in the completed requests
GET entity_exists:<intent_data>
- If the GET returns “true”: this is a confirmed duplicate. The RMS must release the lock (DEL processing:<intent_data>) and return a “Duplicate” failure
- If the GET returns “nil”: This is a new, unique request. The RMS returns a success response to the worker, providing the fencing_token that it generated
{
"session_id": <session_id>,
"status": "SUCCESS",
"fencing_token": <fencing_token>,
"expiration_time": <timestamp>
}
When the worker receives a successful response:
- It performs the minimal DB write. This write must include the unique intent_data and the fencing_token received from the RMS.
Note: the fencing token is stored to prevent out-of-order writes from stale, expired lock holders. The database should also have a UNIQUE constraint on the intent_data column as a final failsafe.
INSERT INTO <table> (id, data, status, last_fencing_token)
VALUES ('some_id', <intent_data>, 'PROCESSING', <fencing_token_from_RMS>)
- Handling a failed SQL write: if this INSERT fails, the saga has failed. The worker must notify the RMS to release the lock.
- On a successful SQL write: The worker immediately notifies the RMS that the intent is permanently registered. The RMS then finalises the reservation:
MULTI
SET entity_exists:<intent_data> "true"
DEL processing:<intent_data>
EXEC
- Note: The two commands are executed atomically using MULTI/EXEC to ensure the processing lock is released if and only if the permanent entry is created.
Step 2: Trigger the remaining operations
With the intent successfully registered and the "fail-fast" check complete, the worker can now safely invoke the remaining asynchronous, heavy operations (the rest of the saga) without fear of duplicates.
What if the DB operation cannot be broken down?
The solution so far assumed the initial database write was minimal and fast. However, there are situations where this operation is monolithic and cannot be broken down.
In this scenario, the "fail-fast" check remains the same, but we must adapt the flow to handle the long-running operation without the reservation lock expiring.
Identifying the intent (Unchanged)
The "intent" is still the unique identifier for the request. If a simple ID isn't available, this can be a hash of the request data. This part of the logic does not change.
Extending the lock with a heartbeat
The core challenge is now lease management. If the lock expires while the heavy operation is still running, a duplicate request could acquire the lock, leading to a race condition.
The solution is a “heartbeat lease extender”:
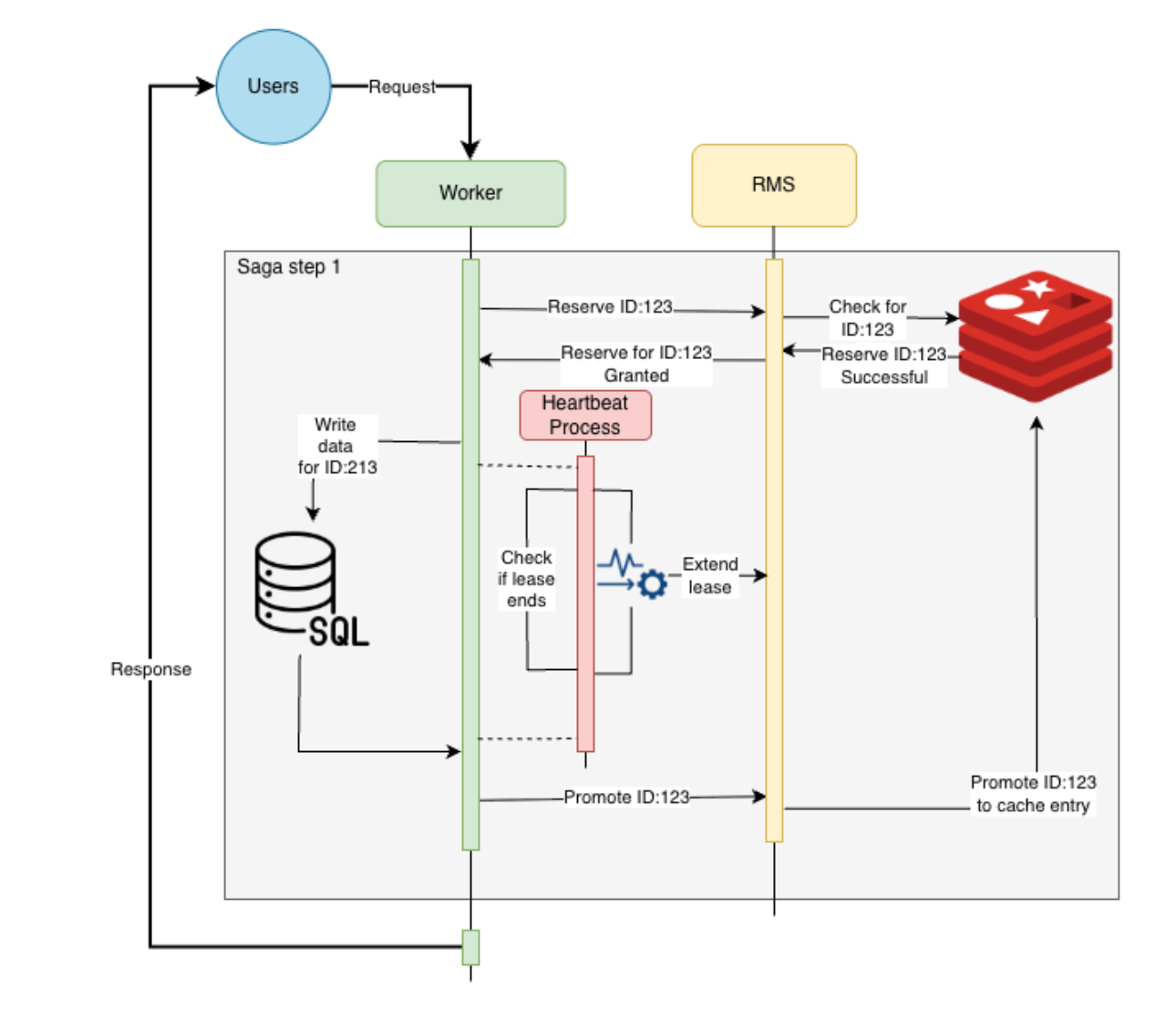
- The worker (Saga Orchestrator) secures the lock from the RMS exactly as described in "Step 1: Reserving the intent" (receiving a fencing_token and a short lease).
- Knowing the operation will be long, the worker immediately starts a background heartbeat process that runs in parallel with the heavy database operation.
- This heartbeat process periodically (e.g., every N seconds, well before the lease expires) calls the RMS to "nudge" the lock and extend its lease.
This "nudge" operation must be atomic and must verify the fencing token to prove ownership.
-- KEYS[1] = The lock key (e.g., "processing:<intent_data>")
-- ARGV[1] = The expected value (e.g., "<session_id>:<fencing_token_from_RMS>")
-- ARGV[2] = The new expiration time in seconds (e.g., 30)
if redis.call("GET", KEYS[1]) == ARGV[1] then
-- This is the correct owner; extend the lease
return redis.call("EXPIRE", KEYS[1], ARGV[2])
else
-- Someone else has the lock, or it expired. Fail.
return 0
end
Finalising the operation
- On Success: Once the heavy database operation finally completes, the worker stops the heartbeat process. It then proceeds with the same final step as before: it notifies the RMS of the success. The RMS then atomically promotes the lock to entity_exists and deletes the processing key.
- On Failure: If the database operation fails, or the heartbeat fails to extend the lease (e.g., the worker dies), the lock will eventually expire, allowing other requests to proceed. The saga fails, and a compensating recovery process can be invoked.
Conclusion and Trade-offs
By using a saga and the reservation pattern, we’ve successfully implemented a high-performance and scalable “fail-fast” solution. Duplicates are now rejected in milliseconds by Redis instead of by an expensive operation in a distributed database.
However, this comes at the cost of added complexity. A new service and dependency (the RMS and Redis) must be maintained, and the logic for long-running operations requires a careful 'heartbeat' implementation to manage the reservation lease.
Ultimately, this pattern demonstrates a powerful principle: offloading critical integrity checks from a heavy, persistent database to a lightweight, in-memory store is a key strategy for building high-throughput, resilient distributed systems.