Introduction
Large Language Models (LLMs) have rapidly transformed from experimental curiosities into powerful tools with vast potential to revolutionise industries. Their ability to comprehend and generate human-like text, translate languages, summarise complex documents, and even provide insightful answers has opened countless doors to business applications. However, the journey from a promising prototype to a reliable production system is fraught with challenges.
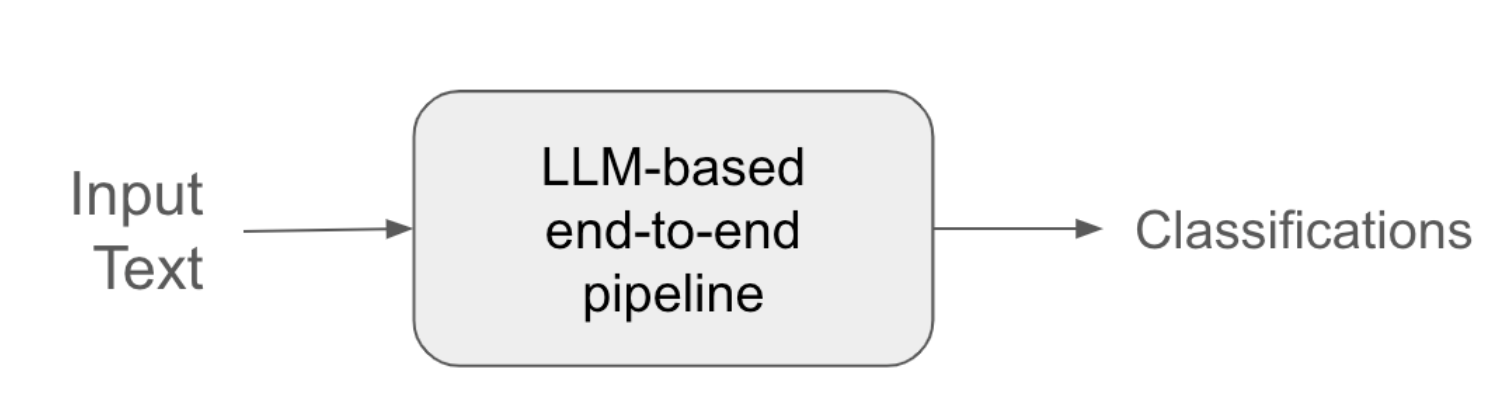
In general, for any Machine Learning (ML) system, of which LLMs are a part, the goal is to model a system in such a way that it produces the desired output for a specific given input. For example, as shown in the diagram below, consider an ML pipeline that uses an LLM to classify certain labels. This involves identifying certain types of entities that fall in a particular category. As a result, there can be various types of false positives, such as hallucinations where an identified entity doesn't exist in the content or an entity is wrongly classified. Similarly, there might be false negatives where an entity that is supposed to belong to a certain category is not identified as such by the pipeline. Thus, the goal of a ML pipeline like the one below is to reduce the number of false positives and negatives as much as possible.
Hallucinations: The Achilles' Heel of LLMs
One significant hurdle in deploying LLMs in business settings is the issue of "hallucinations." LLMs, despite their impressive capabilities, can sometimes generate outputs that are factually incorrect, nonsensical, or deviate significantly from the provided data. These hallucinations can stem from various factors, including biases in training data, limitations in the model's understanding of the world, or even the inherent probabilistic nature of language generation. In a business context where accuracy and reliability are paramount, hallucinations can undermine trust and lead to costly errors. To mitigate these hallucinations, developers are exploring "agentic patterns".
Agentic Patterns
To combat the problem of hallucinations and unlock the true potential of LLMs, researchers and engineers are exploring innovative approaches. One promising avenue is the use of agentic patterns, which aim to imbue LLMs with a degree of agency. This enables them to reason about their own thoughts, reflect on their outputs, and even engage in a form of self-critique. Here are some of the approaches that could be adopted to improve the performance of the systems using LLMs.
Reflection
This pattern prompts LLMs to critically evaluate their own responses, considering factors such as confidence levels, potential biases, and alternative interpretations. Reflection involves the LLM asking itself: 'Am I relying on stereotypes? Are there other plausible explanations for this data? How confident am I in this specific piece of information?'. As LLMs become increasingly integrated into decision-making processes, ensuring their reliability and trustworthiness is paramount. Reflection is a mechanism for LLMs to critically examine their own outputs, mitigating the risks of misinformation and bias.
With a reflective element, LLMs can become more self-aware and less prone to generating unfounded or misleading information.
LLM-as-a-judge
This reflective process can be expanded by bringing in a second LLM to act as a judge, a powerful solution popularly known as LLM-as-a-judge. This approach leverages the reasoning capabilities of LLMs to evaluate the outputs of other LLMs or systems. It essentially acts as an automated reviewer, providing feedback and assessments.
This could be done in a number of ways. The judge could be asked to provide feedback on a response by giving a score from 1 to 10 or giving a boolean value (True/False) on whether or not it agrees with a value (useful especially for classification tasks).. For example a prompt could be:
“Given the context of this news article, rate the factual accuracy of the following summary on a scale of 1 to 10” or it could be something like this - “Does the following classification of this customer review as 'positive' align with the sentiment expressed in the text? Answer True or False”.
LLM-as-a-judge can help in reducing the false positives, especially the hallucinations, by bringing in critical thinking to see if an entity does indeed belong to a particular class. For example, if the classification system labels a product review as 'positive' based on a hallucinated feature, the LLM-as-a-judge can identify the discrepancy by comparing the classification to the actual content of the review.

To some extent, this mitigates the reliance on humans to constantly check if the values are indeed correct. This solution is especially powerful when the system in the example above processes a large volume of text data stream on a daily basis.
In the ideal scenario, we aim that the judge can perform at the same level as a human reviewer. This ensures that the ML pipeline behaves as expected as we have a reviewer that can point out potential misclassifications. However, achieving this requires mitigating the challenges that come with using the LLMs. For example, the LLM-as-a-judge could exhibit bias, have contextual understanding limitations, or show variability in its performance.
In the meantime, we can use an LLM-as-a-judge in an iterative process for our business use case.
- We will start by using it for observability and to mine hard examples. This will improve the performance of the ML pipeline and refine the LLM's own review capabilities.
- Human reviewers can analyse cases where the judge's assessment deviates significantly from their own. These 'hard examples,' which often involve nuanced language or complex reasoning, are used to refine the judge's prompts or training data.
- In the longer term, this helps us to “build trust” with the LLM-judge as it gives us enough time to know about the inherent limitations and we can benchmark its performance against a human reviewer.
- During this process, it is very important to have a human-in-the-loop to continuously monitor the performance of the LLMs.
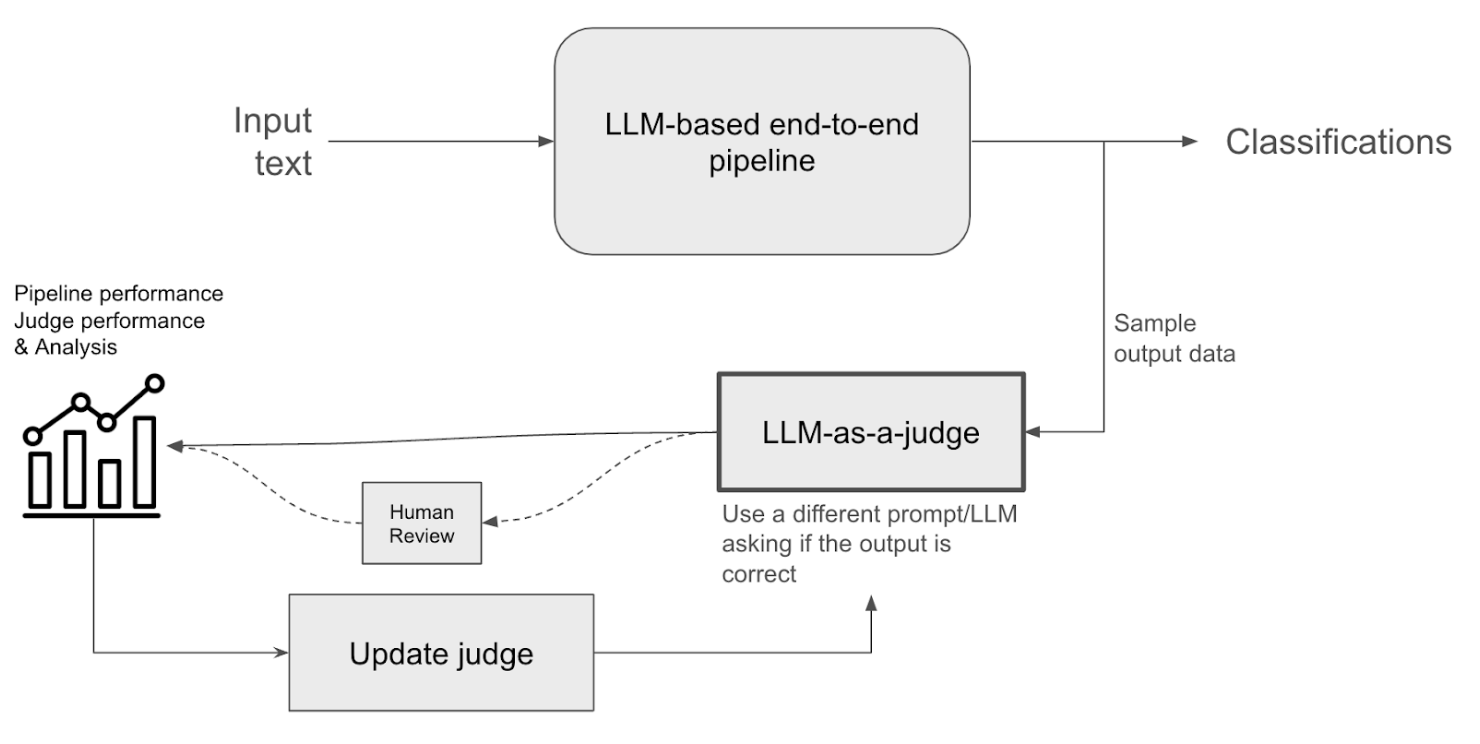
As shown in the diagram below, a subset of the output classification stream can be fed into LLM-as-a-judge.
- The judge's output, which can be a score or a binary value (disagreement), is fed to an observability tool. This helps to give an idea of how the ML pipeline is performing.
- And at the same time, a human reviewer examines the outputs of the ML pipeline and the judge to identify the hard examples where the judge was incorrect.
- These examples are fed back to the judge, which in turn helps it to make better judgements for the forthcoming output stream.
Chain of Thought
This pattern encourages LLMs to generate a series of intermediate reasoning steps before arriving at a final answer. By explicitly articulating their thought process, LLMs can expose potential errors and inconsistencies, which lead to more accurate and reliable outputs. Unlike direct-answer prompting, CoT guides the model to work through these reasoning steps, making it more adept at solving complex tasks like math problems, common-sense reasoning, and symbolic manipulation.
This approach’s true benefit lies in addressing a huge challenge in machine learning models: the lack of transparency. Traditional classification models, while powerful, often function as black boxes. They ingest/receive input data, process it via a complex algorithm, and produce a label as output. While the accuracy of the result might be high, the model rarely provides insight into its decision-making process. This lack of transparency can be a significant drawback, particularly in critical applications where understanding the rationale behind a classification is crucial.
Chain-of-thought (CoT) reasoning can enhance tasks like classification. Instead of simply predicting a label, we fine-tune the model to generate a sequence of reasoning steps that explain its classification decision.
As an example, consider an ML system that classifies forum posts into "Toxic", "Misinformation", "Neutral", or "Both" (toxic and misinformation) and provides a reasoning chain.
Here is a post that the ML system receives:
"Forget your 9-to-5 grind. I made $50,000 last month with the 'Random Arbitrage' crypto bot. It's a guaranteed, zero-risk investment system that the big banks are trying to suppress. Anyone calling it a scam is just a paid shill trying to keep you poor."
If we consider the direct-answer prompting approach, a simple prompt would be something like this - Classify this post as Toxic, Misinformation, Neutral, or Both. The classifier with this simple prompt might detect the negative language and classify it as "Toxic." However, it might miss the misinformation aspect or the combined issue.
However, here is a prompt that is enhanced to include the reasoning aspect -
Classify forum posts into "Toxic", "Misinformation", "Neutral", or "Both" (toxic and misinformation) and provide a reasoning chain.
The response for the above post example might look like this:
Let's break down the post. First, the statement "It's a guaranteed, zero-risk investment system" is a classic hallmark of financial scams and is factually incorrect; all investments carry risk. This is a form of misinformation. Second, the claim that "Anyone calling it a scam is just a paid shill" is an aggressive ad hominem attack designed to shut down debate and discredit critics. This creates a hostile and manipulative environment, which is toxic. The post uses a false promise (misinformation) to legitimize its claims and insults (toxicity) to defend itself. Therefore, the post is best classified as containing both.
Correct Answer: Both
This example shows how CoT is crucial for identifying misinformation that isn't a complex conspiracy theory but a harmful, false generalisation. The reasoning chain makes it clear that the model understands that the stereotype itself is a form of misinformation, and the resulting call to action is toxic, leading to the correct and fully justified classification.
As the example shows, CoT requires nuanced understanding, such as identifying derogatory terms and false claims, beyond simply recognising negative words. The classifier also needs to understand the context of the claims to determine their nature such as whether it is misinformation or an opinion.
CoT helps the model accurately identify both the toxicity and misinformation aspects of the post, leading to the correct "Both" classification. The reasoning chain explains why the post is classified as such providing valuable insights for moderation or analysis and allowing for further prompt fine-tuning. In real-world scenarios, this makes the ML system more transparent, especially critical in sensitive application like moderation and checks for financial institutions. Ultimately, CoT guides the model to lay out its reasoning process, often resulting in more accurate and interpretable outcomes.
This is an active research area with many COT-Based prompting techniques. One popular, simple and yet incredibly effective technique is zero-shot chain-of-thought. It has been found that by simply appending the words "Let's think step by step." to the end of a question, LLMs are able to generate a chain of thought which leads to more accurate answers.
CoT can significantly improve the performance of classification systems in complex scenarios that require nuanced understanding, multi-step reasoning and better transparency of the model's thinking.
Metaprompting
Metaprompting involves providing LLMs with additional instructions or feedback within the prompt itself. By incorporating meta-level information, users can guide the LLM's behavior and steer it towards desired outcomes.
Metaprompting adds context and direction to the prompts. It’s about going beyond a simple request like ‘Write a story” to something more instructive such as “Write a story, but act as a seasoned fantasy novelist who focuses on character development”. This additional layer of instruction, the "meta" part, tells the LLM how, emphasising the procedural aspects of problem-solving ('the how') over content-specific details ('the what').
Metaprompting can include the following meta-level information:
- Instructions from prompt generation: Guide the AI to create prompts for specific tasks, such as summarising text, answering questions, or generating different creative text formats.
- Constraints on the output: Specify the desired length, style, or format of the response, ensuring the output aligns with the user's needs.
- Feedback on previous responses: Provide the LLM with information on the strengths and weaknesses of its previous outputs, allowing it to learn and adapt its responses over time.
- Contextual information: Provide background details or relevant context to help the AI understand the nuances of the task and generate more relevant responses.
By incorporating this meta-level information, users can effectively "teach" the LLM how to generate better prompts leading to more accurate, relevant, and creative outputs. Providing clear instructions and constraints through metaprompting focuses the LLM’s attention, reduces ambiguity, and leads to more accurate and relevant responses.
For instance, the previous example about classifying toxic posts can be further elaborated with meta-prompting by making use of additional tools
"Task: Classify the following post as either Toxic, Misinformation, Neutral, or Both.
Definitions:
Toxic: Content that is hateful, abusive, or intended to harm or offend.
Misinformation: Content that presents false or misleading information.
Neutral: Content that is objective and does not contain harmful or false information.
Both: Content that exhibits characteristics of both Toxic and Misinformation.
Post:
[Insert the post here]
Tools:
Sentiment Analysis Tool: Use this tool to analyse the post's language and determine if it expresses negative emotions or contains hateful/abusive language.
Fact-Checking Tool/Web Search: Use this tool to verify any factual claims made in the post. Search for credible sources to confirm or deny the information.
Instructions:
First, use the Sentiment Analysis Tool to determine the emotional tone of the post.
Next, use the Fact-Checking Tool/Web Search to verify any factual claims.
Based on the results from both tools, analyze the post and provide the single most accurate classification from the provided categories.
Output:
Provide only the classification label: (Toxic, Misinformation, Neutral, or Both)."
This approach helps to break down the task into sub-tasks, such as analysing the language for toxicity and fact-checking for misinformation. It also utilises additional tools for tasks like analysis, fact-checking, or accessing information databases.
Using these tools improves the ML system's performance in a number of ways. For example, sentiment analysis helps to access factual information that is required to produce the output. It reduces the false positives that arise from interpreting unfamiliar or niche information as false. The step-by-step instruction (analyse sentiment, fact-check, classify) guides the classifier through a logical process, which reduces the chance of errors due to haphazard analysis.
By setting clear definitions, using defined tools, and creating a structured prompt, the process becomes less reliant on subjective interpretation and more reliant on objective data. This results in more accurate classifications and a significant reduction in false positives.
DSPy
As you might have already guessed, an effective prompt is a critical aspect of harnessing the power of LLMs. Crafting the right prompt, also known as prompt engineering, can significantly impact the quality and relevance of an LLM's output. However, considering that searching for the right prompt is an open-ended challenge, this can very often be a time-consuming process. Thus, an automated process that helps narrow down the best prompt for a given task would be highly beneficial.
DSPy, a domain-specific programming language designed for prompt engineering, has emerged as a valuable tool in this regard. DSPy streamlines the process of prompt iteration, allowing developers to rapidly experiment with different prompt structures, parameters, and strategies. By facilitating quick and efficient experimentation, DSPy accelerates the development of prompts that elicit desired behaviours from LLMs.
The Road Ahead: From Research to Real-World Applications
While the journey from prototype to production is still ongoing, the potential of LLMs in business is undeniable. From automating customer service interactions to generating personalised marketing content, LLMs are set to transform the way businesses operate. By addressing challenges like hallucinations and leveraging tools such as agentic patterns and DSPy, we can pave the way for a future where LLMs are seamlessly integrated into the fabric of business, driving innovation, efficiency, and growth.
Ethical use
While the potential of LLMs to revolutionise business is undeniable, we must acknowledge the ethical complexities that accompany their deployment. These powerful LLM-based tools raise critical questions that demand careful consideration and we must implement safeguards to ensure their ethical use. For instance, businesses must prioritise rigorous bias detection and mitigation strategies since the LLMs are trained on vast datasets, which can inadvertently perpetuate existing societal biases. Such actions could prevent discriminatory outcomes in applications like hiring, loan approvals, or customer service interactions.
Key Takeaways
- LLMs offer significant potential for business applications but also come with challenges like hallucinations.
- Agentic patterns like Chain of Thought, Reflection, and Metaprompting can enhance LLM reliability.
- DSPy streamlines prompt engineering, accelerating the development of effective prompts.
- The future of LLMs in business is promising, with continued research and development paving the way for widespread adoption.
While LLMs hold great promise, it's essential to approach their deployment with a realistic understanding of their capabilities and limitations. Responsible and ethical use, coupled with ongoing research and development, will be key to unlocking their full potential in a business context.