
In today's data-driven world, applications need to communicate with each other instantly and reliably. From processing real-time payments to tracking customer activity, the sheer volume and velocity of information can be overwhelming. This is where leveraging real-time data streaming solution, such as Kafka, can be instrumental in ensuring your applications can achieve this.
Kafka is a framework, built primarily for data streaming pipelines, and acts as a an orchestrator for all your data, allowing different systems to publish to and read from event streams in a way that is both scalable and fault-tolerant.
At its core, Kafka allows services to produce (send) and consume (read) messages. But how does it do this, when dealing with enormous volumes of data, whilst ensuring it is processed in real-time and without any data loss. With ever increasing focus on message and event processing across all our services in Comply Advantage, let's dive into the fundamental concepts you need to know to work with it effectively.
The Core Architecture: Topics, Partitions, and Brokers
Before we dive right into the data streaming process, let's look at where that data lives within the Kafka cluster.
Topics and Partitions
Kafka is a distributed log, meaning scalability and reliability are built into its core purpose.
Data is organised into topics, and these topics live within the Kafka cluster. To allow for scale, as many applications that leverage data streaming require, these topics are broken down into partitions. When creating a topic, the number of partitions per topic and the replication factor of the topic (the number of copies of data stored), need to be provided. Partitioning allows data for a single topic, to be distributed across a multiple brokers.
When a message enters a topic, it consists of an optional key, and a value. The partition that a message goes to, is determined by hashing the message key, which means that all messages with the same key, will always go to the same partition. This is a crucial part in ensuring the processing order for a specific entity, such as a single user's activity across an application, is maintained.
Replication and Leaders
Once the partitions are distributed across the brokers, a leader is elected. Every partition has one leader, and if the partition has replicas, these act as followers, reading messages from the leader. In a case where a broker goes down, one of the in-sync followers becomes the new leader, ensuring your data streaming pipeline is resilient.
Producers/Consumers connect to that leader by default, however they can be configured to connect to the closest follower, in situations where it makes more sense to do so, such as across different data centers.
Sending Messages: The Producer
Producers are responsible to writing the data to Kafka topics. Messages sent by producers are always processed by Kafka as a byte array, as it doesn't care about underlying data types, giving greater flexibility in configuring your data streaming pipelines. However, in order to avoid data loss, it's crucial to configure producers correctly to ensure reliability.
Acknowledgements and Idempotence
When a producer sends a message to a Kafka topic, it will expect an acknowledgement (ack) from the broker on receipt of the message. You can configure the level of acknowledgement required for your application, which requires a carefully thought out balance between latency and durability. The right approach will vary from project to project.
Acknowledgements:
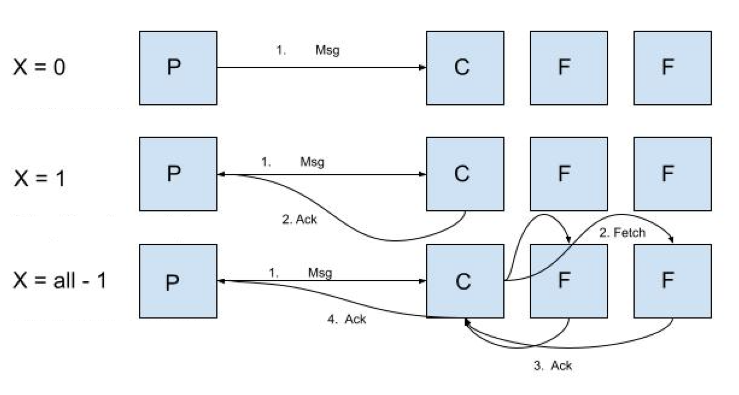
Above you can see the varying acknowledgement flows, which account for:
X = 0: Lowest latency option, that does not require the broker to acknowledge the receipt of the message. With this approach, there is no way to ensure that the message has been received or adequately replicated, therefore sacrificing the durability aspect of the data streaming pipeline.X = 1: Only the leader needs to acknowledge the receipt of the message, this increases the latency, but ensuring that the message has been received by the broker. Since acknowledgement from the followers is not required, this approach cannot ensure that the required replication has been accomplished.X = All - 1: This approach guarantees that the message is successfully written to a minimum number of in-sync replicas before an acknowledgement is sent to the producer. This is the higher durability option, but also the highest latency one too.
By default, brokers in Kafka are designed to accept incoming messages without requiring any validation, which can lead to data replication due to the above delivery guarantees. To prevent this, you can set enable.idempotence=true, which ensures that messages are delivered exactly once, in the correct order, with almost no performance impact.
Reading Messages: Consumers and Offsets
Consumers are responsible for reading the data from the topics. They operate in consumer groups, and how these should be coordinated, will depend on your specific use case.
Consumer Groups and Assignment Strategies
A consumer group is a grouping of one or more consumers, working together, in order to process data for a topic. By default, Kafka will divide the partitions of a topic among the consumers in a group. If you have a topic with 4 partitions, and a consumer group with 4 consumers, each consumer will read messages from a single partition, ensuring that data across the partitions is processed in parallel.
The data inside the partitions themselves will be ordered, however, there is no guarantee that the messages will be consumed in any given order when using multiple partitions.
In Kafka, the broker acts as a group coordinator. If a consumer dies, the broker will detect this, and trigger a consumer rebalance, reassigning the partition to the remaining consumers in the group.
When creating a consumer, the rebalance can be configured through the use of a specific assignment strategy. Assignment strategies are methods in which the partitions are divided between the consumers, with different strategies leading to more efficient reassignments of consumers.
- Round Robin Assignor: assigns a partition to a consumer one by one. This is not very efficient as each partition will be reassigned.
- Sticky Assignor: When a rebalance takes place, it will attempt to changes as little as possible, moving only the partitions from the dead consumer. This is a more efficient approach.
- Static Assignment: Gives consumers an ID. If after 5 minutes, the consumer comes back on, use ID to reassign their assignments. Need to have assigned an identity for consumers, as well as increased session timeout.
- Cooperative Sticky Assignor: An improvement on the Sticky Assignor, that allows consumers to keep processing their data during a rebalance, minimizing any processing downtime, before redistributing those partitions.
Offsets: Bookmarking your progress
So how does a consumer know which messages it has already read? Each message in a partition, has a unique, sequential identifier, called an offset.
An offset is essentially a position within the partition, that determines which message is to be consumed next, acting as a bookmark for the partition.
By default, Kafka stores these offsets in an internal topic called __consumer_offset, this being the most common and recommended approach, as it's managed by Kafka itself.
Putting It All Together
From producers ensuring data reliability, to consumer groups processing the messages in parallel, Kafka's architecture provides a powerful framework for building real-time data applications. Alongside these, the core concepts of topics, partitions, and offsets, build the foundations of a scalable, resilient and fast system.