
The emergence of Large Language Models (LLMs) has led to a significant shift in momentum in recent years towards developing agentic systems. These systems look to leverage LLM abilities of interpreting unstructured data and planning actions dynamically, aiming to automate and streamline what would otherwise often be a complex workflow. However, to deliver real value, these foundational LLMs often need access to information only available outside of their internal training data - whether it's interacting with APIs, querying databases, or understanding specific environments like your codebase. This is where development often hits a snag.
Connecting an agent's powerful 'brain' to the necessary tools and data sources can be a major challenge. Without clear standards, developers spend time building custom connectors for every data source and external tool. These bespoke integrations are not only slow and repetitive to build, but they often result in brittle systems that are harder to scale effectively.
This is where Model Context Protocol (MCP) comes in - a new open-source standard of communication released by Anthropic that bridges the gap between agents and the outside world. The rest of this post will explore the benefits of using this standard for building agentic workflows and walk through a practical example of how you might use it.
Core Principles of MCP
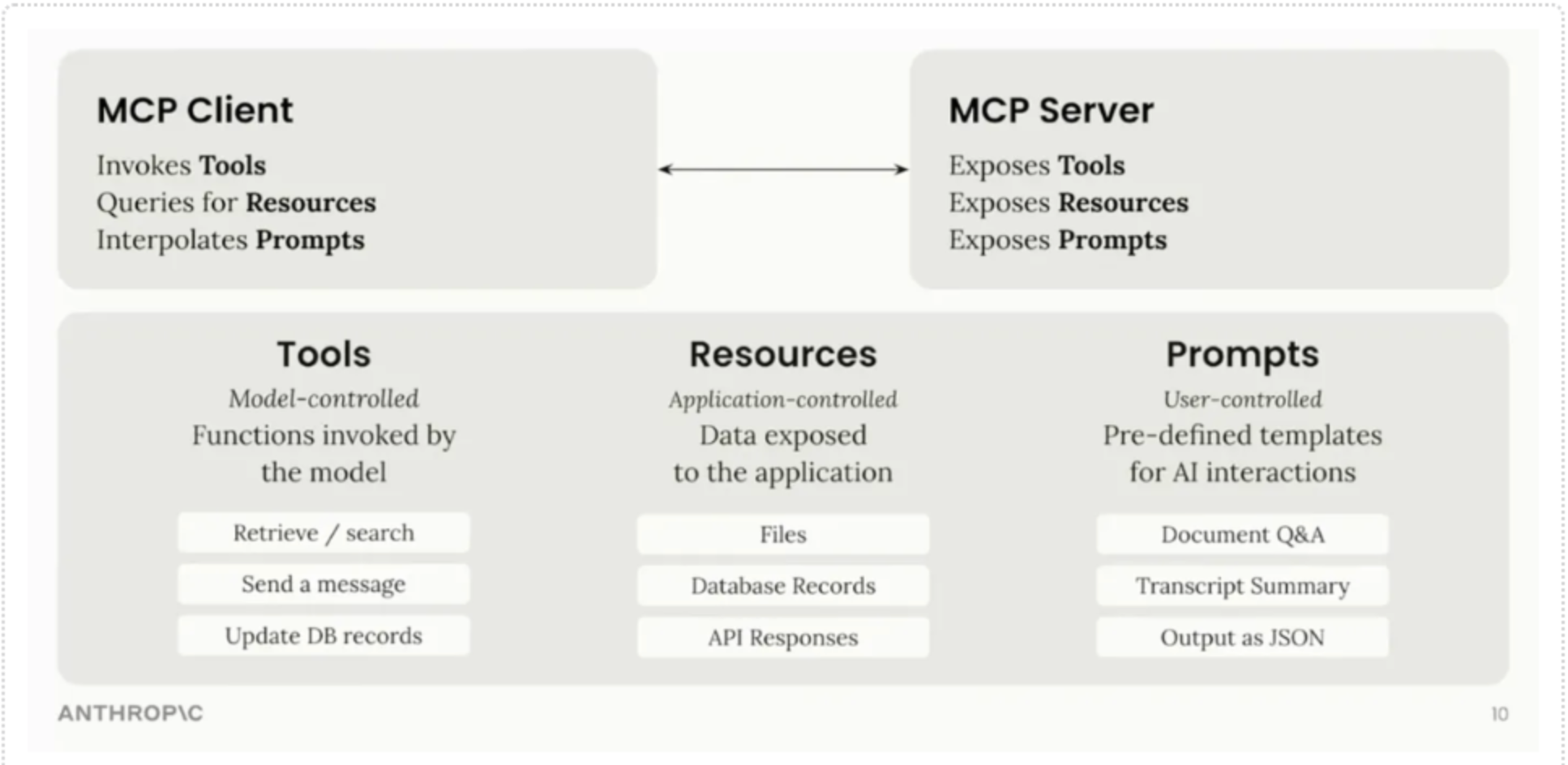
As mentioned above, MCP aims to standardise how an LLM can interact with external data and tools. It achieves this by using specific building blocks, known as primitives, and a defined client-server architecture. Let's look at these core components.
Building Blocks
- Tools: Executable functionality that allows the LLM to take actions on external systems. Each tool has a standard definition describing what it does and what inputs it needs.
- Resources: Data or additional context that can be provided to the model. This could be anything from the content of a file (file:///...) to a database schema (database://.../schema) or dynamic information. An example of this can be seen when you attach a file to chat clients like Claude.
- Prompts: Pre-defined templates that a client or user can invoke (e.g., a template for summarising text).
MCP Architecture

- Servers implement the logic of interacting with a specific system. This could be connecting to a database and executing queries, wrapping an API and transforming the data into a specific format, or providing access to some kind of file system. It then exposes these capabilities using the Tool and Resource definitions.
- Clients live within the agent and can communicate with any compliant MCP Server to discover and use the capabilities offered.
Benefits of this approach
- Because all tools are discovered and called using the same protocol methods (list_tools, call_tool), the agent doesn't need custom logic for every specific API or function it interacts with.
- Similarly, because resources are identified and read using standard protocol methods (list_resource_templates, read_resource) via URIs, the agent can consume context from diverse sources without needing bespoke code for each type.
- Decoupled architecture allows developers to create independent, specialised, and highly reusable MCP servers.
- eg. A team builds an MCP server to query user data within an internal database. Now, any future AI agent needing access to that user data can simply connect to that existing server. The integration work is done once.
Putting it all together
It's all well and good to understand how MCP works, but I often find the best way of understanding the benefits is to apply what we learn. Let's do this by creating a proof of concept (POC) that models a critical problem in the compliance space: Politically Exposed Person (PEP) Enrichment.
What is PEP Enrichment?
Keeping track of PEPs is a core part of effective risk and compliance screening. Many of these PEPs also have relatives or close associates (RCAs) who warrant consideration as additional entities clients may wish to screen against. Generally, multiple sources must be consulted to verify this kind of information before enriching existing PEP profiles with this data..
Proof of Concept
In our POC, we'll aim for a very simple user flow that illustrates the core challenges of PEP enrichment:
- Search for PEP data in Wikipedia
- Store this data in our Users table in a database
- Find RCAs of our PEP through web searches
- Corroborate any data we find across multiple search results
- Add any RCAs we find to our database
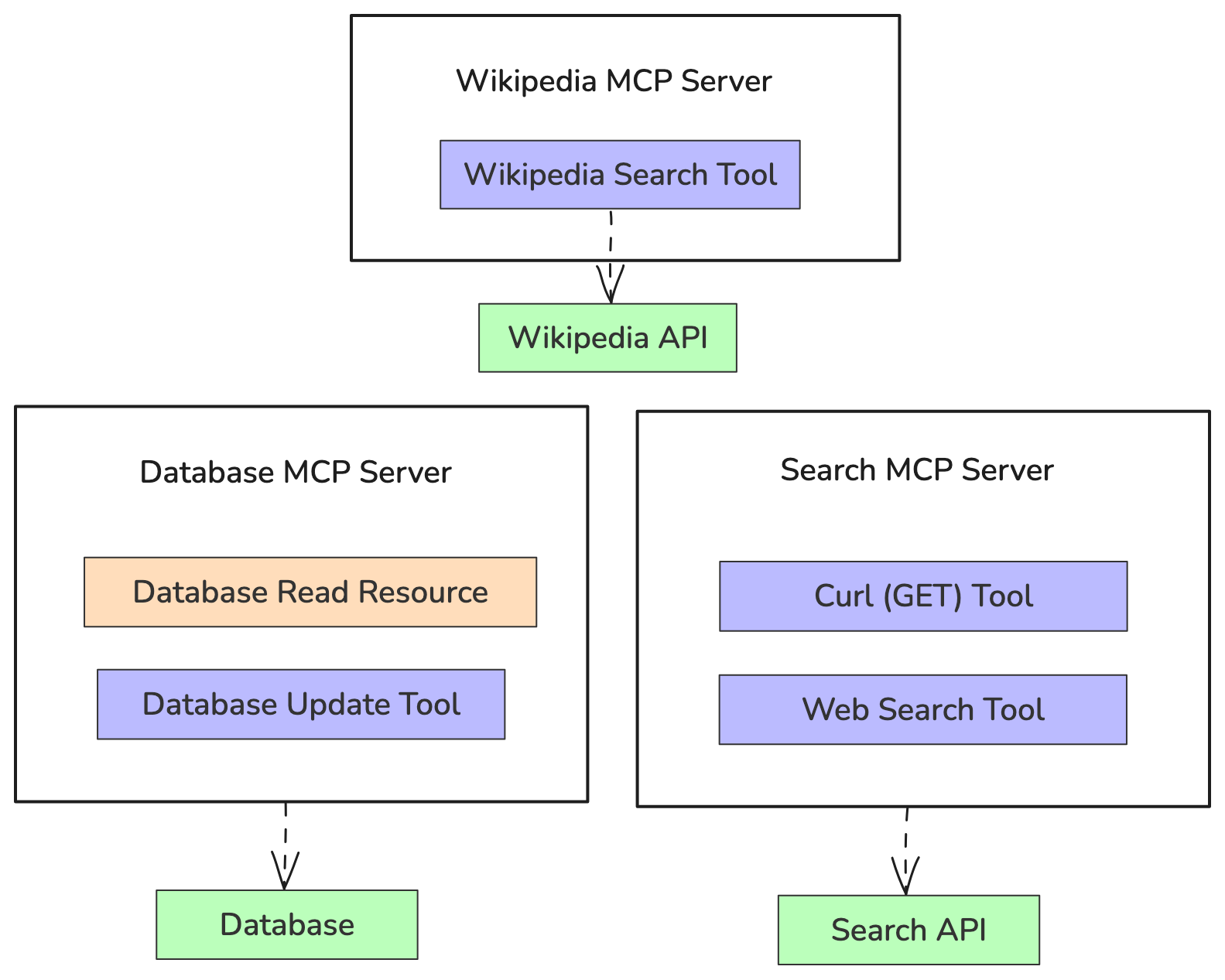
We want to ensure that the only inputs required for our agent are natural language instructions to follow this workflow. To achieve this technically, we need three main capabilities: search and REST API access, Wikipedia data retrieval, and database operations. These can be achieved through 3 MCP Servers:
MCP Servers
- Search MCP Server: This will include tools to fetch from any REST APIs, as well as perform web searches and provide us the top N results. In this case, we'll use DuckDuckGo as our search provider.
- Wikipedia MCP Server: This will include tools to fetch data from Wikipedia.
- Database MCP Server: This will include a resource highlighting our user table schema, as well as tools to allow for execution of SQL to add, update or delete user data.
Tools can include arbitrary execution of some code or result in an action of some kind. Therefore, in a production environment, we would need to include guardrails of some kind such as authorisation checks or santitation of inputs / outputs. For the purposes of this POC, we'll be applying a naive authorisation check prompting the user to accept or reject any tool call proposed by the agent.
Agent and Client Architecture
While the MCP Servers provide the connection points to the database, wikipedia and search APIs, we also need a corresponding host to actually communicate with them using the protocol. For our particular use case, I thought it would be better to engineer our own user interface, complete with our own MCP Clients, as most existing clients with feature support for tools and resources tended to be based inside IDEs or coding assistants.
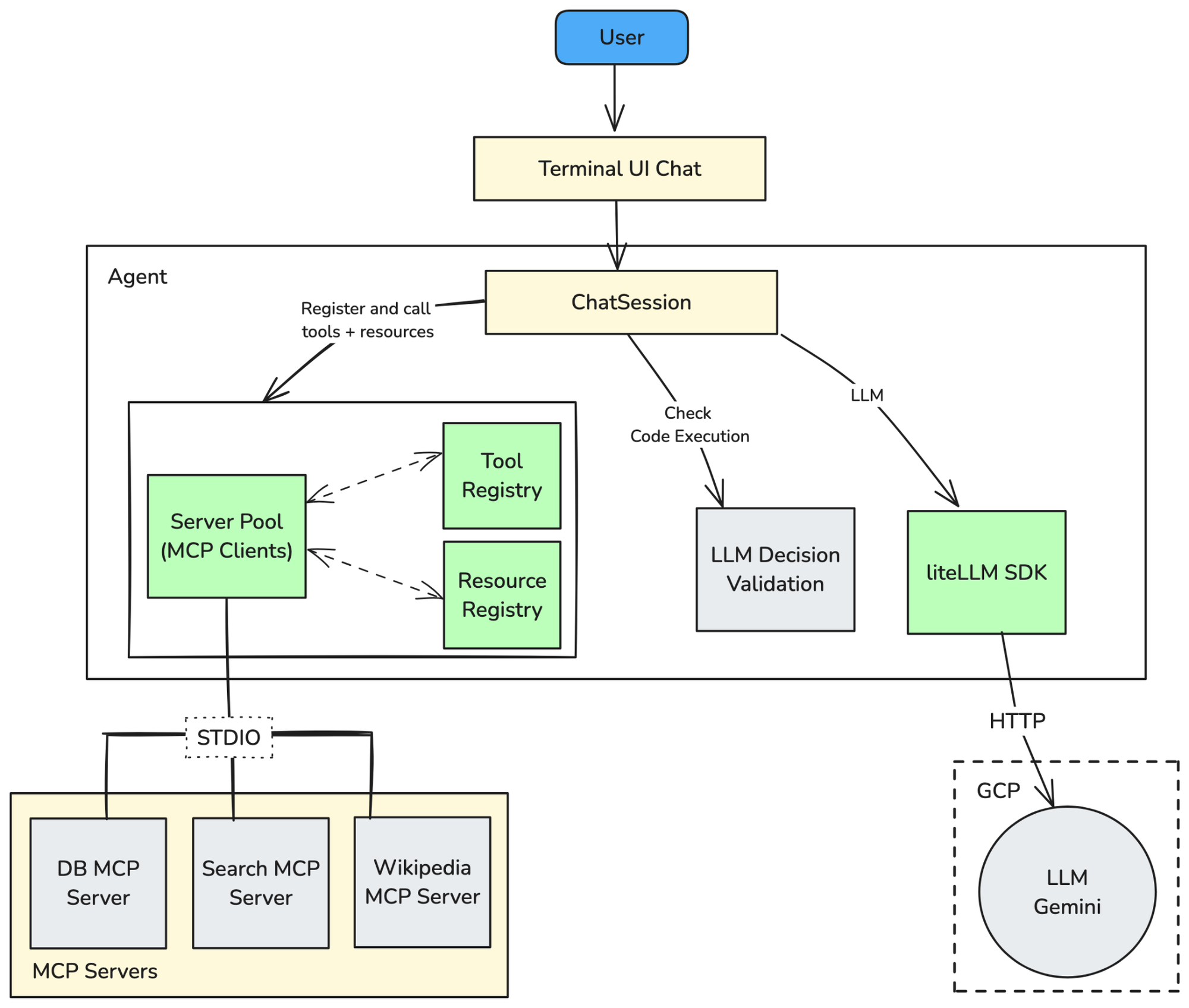
Looking at our architecture diagram, the agent coordinates several key parts to enable MCP interactions through a ChatSession it establishes with the user:
- MCP Connection Management: A crucial piece is managing the connections to the different MCP server processes. In our codebase, the ServerPool reads the server configurations (like which command starts each server) and uses MCP's stdio_client functionality to establish connections via the STDIO (standard input/output) transport layer. This pool maintains a 1-to-1 session between a client and its corresponding server as ClientSession objects and exposes these servers to the agent.
- Discovery & Registration: Once connections are live, the agent needs to know what capabilities each server offers. We implement this using a ToolRegistry and a ResourceRegistry. These components use standard MCP protocol messages (list_tools, list_resource_templates) sent over the established ClientSession objects to discover and catalogue the available tools and resources from all connected servers. The ToolRegistry also plays a vital role in translating the MCP tool definitions into the specific format expected by our chosen LLM (Gemini, accessed via the litellm library).
- Core Agent Orchestration: The main Agent class acts as the orchestrator. It receives user input, interacts with the ResourceRegistry to potentially fetch context, prepares the prompt for the LLM (using litellm), includes the available tools fetched by the ToolRegistry, processes the LLM's response (which might include a request to use a tool), and finally executes actions by invoking the standard call_tool method on the appropriate server's ClientSession.
This setup, built using MCP's standard client libraries and concepts, allows our custom agent logic to discover and use the standardised Tools and Resources offered by the different MCP Servers. The user can then interact with this agent through a terminal UI to create any workflows they can imagine with the tools and resources available to them.
Agentic Examples:
Example 1: Enriching and Storing PEP/RCA Data
In this first example, we ask the agent to find information about a Politically Exposed Person (Rishi Sunak) and potential Relatives or Close Associate (his wife, Akshata Murty and father-in-law N. R. Narayana Murthy), store them in our database, and link them appropriately.
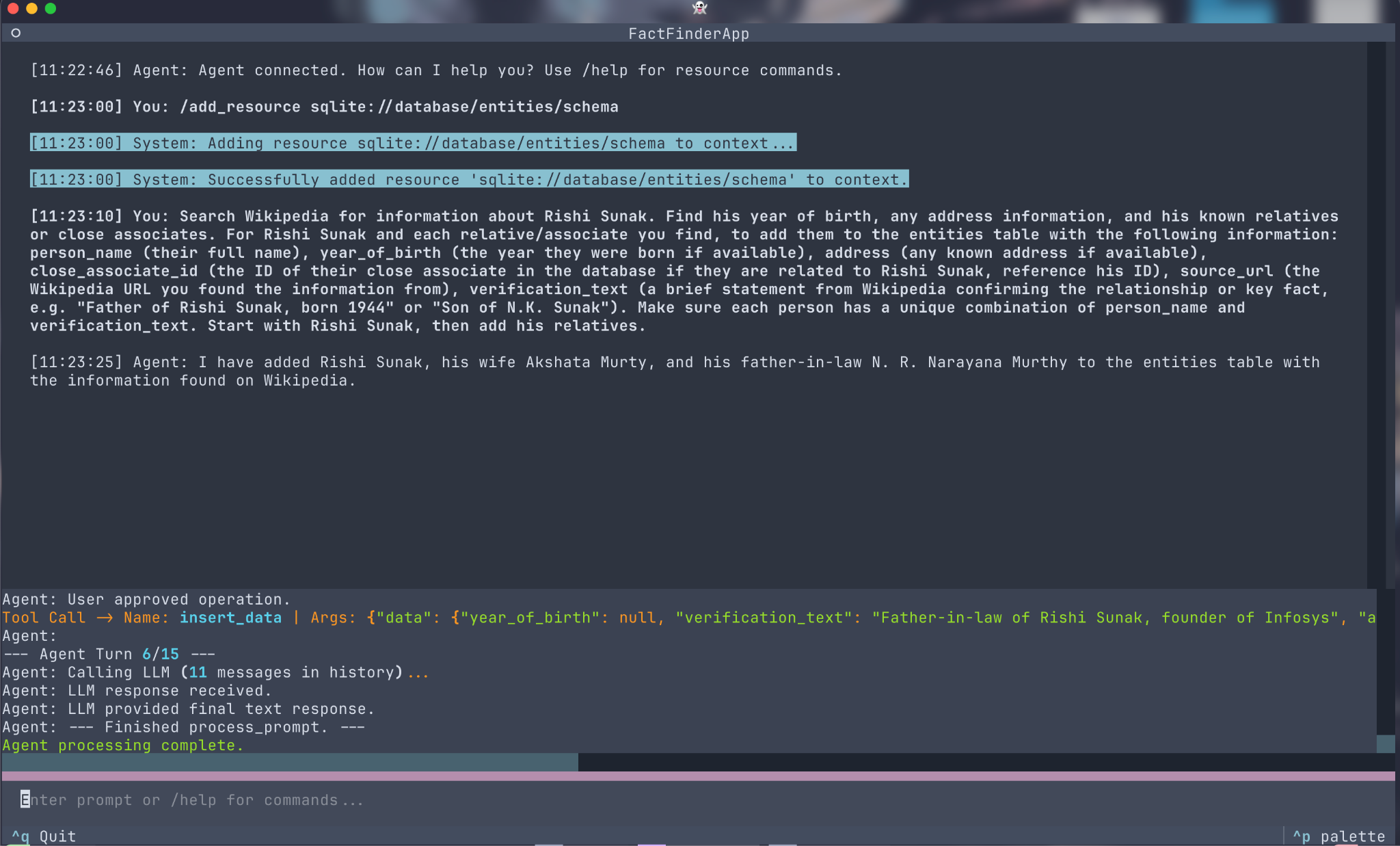
Let's break down what's happening:
- Providing Context (Resource): I provide the agent with the database schema using the command
/add_resource sqlite://database/entities/schema. The agent uses the ResourceRegistry and the read_resource MCP call to fetch this schema from the Database Server, allowing the LLM to understand the target table structure later. - Natural Language Instruction: I give a (fairly verbose) instruction in plain English on what APIs to use when finding data on Rishi Sunak and his wife (Akshata Murty) and how to link them via close_associate_id.
The content required in this instruction for your workflow to execute successfully can vary depending on the language model you choose.
- Outcome: The agent successfully interprets the multi-step request, uses the Wikipedia Server via an MCP tool to gather information, and then uses the Database Server via another MCP tool to store the structured data, confirming completion to the user.
Example 2: Retrieving Stored Data
Now that the data is stored, we can ask the agent to retrieve it, demonstrating interaction with the database via MCP. This is a perfect example of how the same MCP Server could potentially be used by multiple clients for different use cases - in this case, the database server acts as a go-between, providing access to our internal data to the LLM, meaning the end user can get information about PEPs without ever having to connect to a database or an API endpoint themselves.
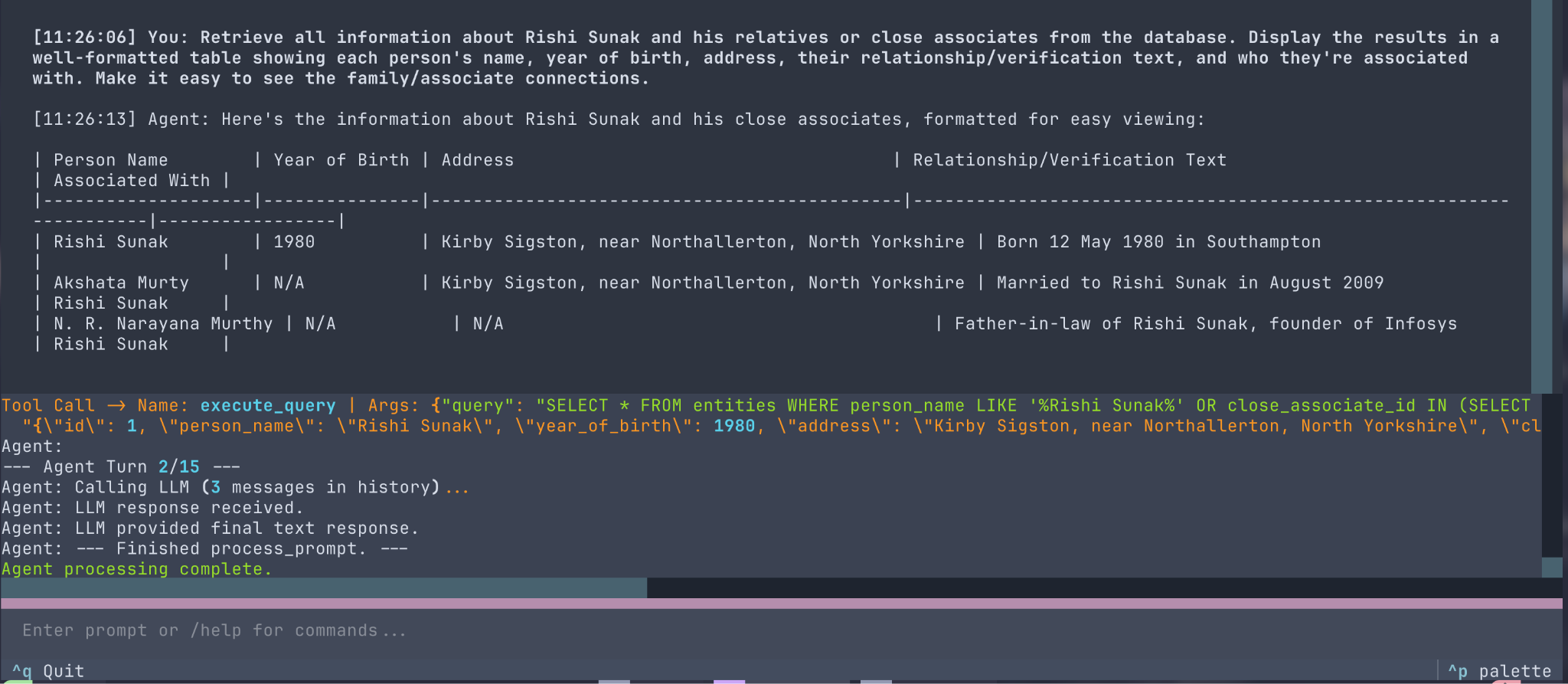
These examples showcase how an agent, powered by the MCP client architecture, can easily orchestrate actions across multiple specialised servers (Wikipedia, Database, Search). It uses standard MCP mechanisms (read_resource for context, call_tool for actions) to interact with the functionalities defined in our servers, which allows the agent to execute complex, multi-step workflows based on natural language alone.
MCP: A Powerful Tool, Not a Silver Bullet
Like almost every piece of software, this is not in fact a silver bullet that solves all the problems in the agentic workflow space. Its core strength is providing a standardised and convenient bridge between AI agents and the many external APIs, data sources, and tools they need to function effectively. Based on our experience building the enrichment POC, a few points warrant further investigation:
- Understanding Primitives in Practice (e.g. Prompts): While Tools (for actions) and Resources (for context) had clear and immediate applications in our POC, the utility of the Prompts primitive (for reusable templates/workflows) was less obvious in this specific project. The protocol also includes support for sampling, which allows servers to request responses by the LLM through the client, giving them even more capabilities. A potential next step for this POC could involve incorporating multiple agents, each using an LLM specialised for a particular task in the workflow. This multi-agent structure seems like a natural scenario where the Prompts primitive and sampling technique would be particularly beneficial.
- The LLM is Still Key: The agent's ultimate success in using the tools and resources we provide to it still hinges on the capabilities of the Language Model itself. eg. We occasionally saw cases during the development of our POC where the model we used outright failed to identify the correct tool to use, or chose to abandon usage of tools altogether and respond with its own internal knowledge.
- Production Considerations: Moving beyond a local POC like ours naturally raises questions about production deployment. Aspects like error handling, observability, authorisation, and input/output sanitation – deliberately simplified in our POC – become critical in a live environment. There's also the challenge of understanding how servers can be reused at scale.
Overall, MCP remains a valuable standard for developing agentic systems. The ability to create custom, reusable servers that expose tools and resources that may be used by an agent seems like the perfect approach to accelerating the development of complex agents, simplifying a critical integration challenge.